Register now for better personalized quote!






























As outlined in my first blog, there is a paradigm shift towards heterogeneous computing. Key drivers being emergence of new workloads in the AI/ML domain requiring best of breed hardware and software framework. While we are going to focus on system architecture trends and requirements driving the need of heterogenous compute, it is worth noting that on the software side similar trend is happening. Plethora of code bases from x86/ARM/MIPS/RISCV, system and function libraries, embedded Kernels, deep learning frame works such as Caffe, TensorFlow, PyTorch dominate a software platform to optimize the execution time.
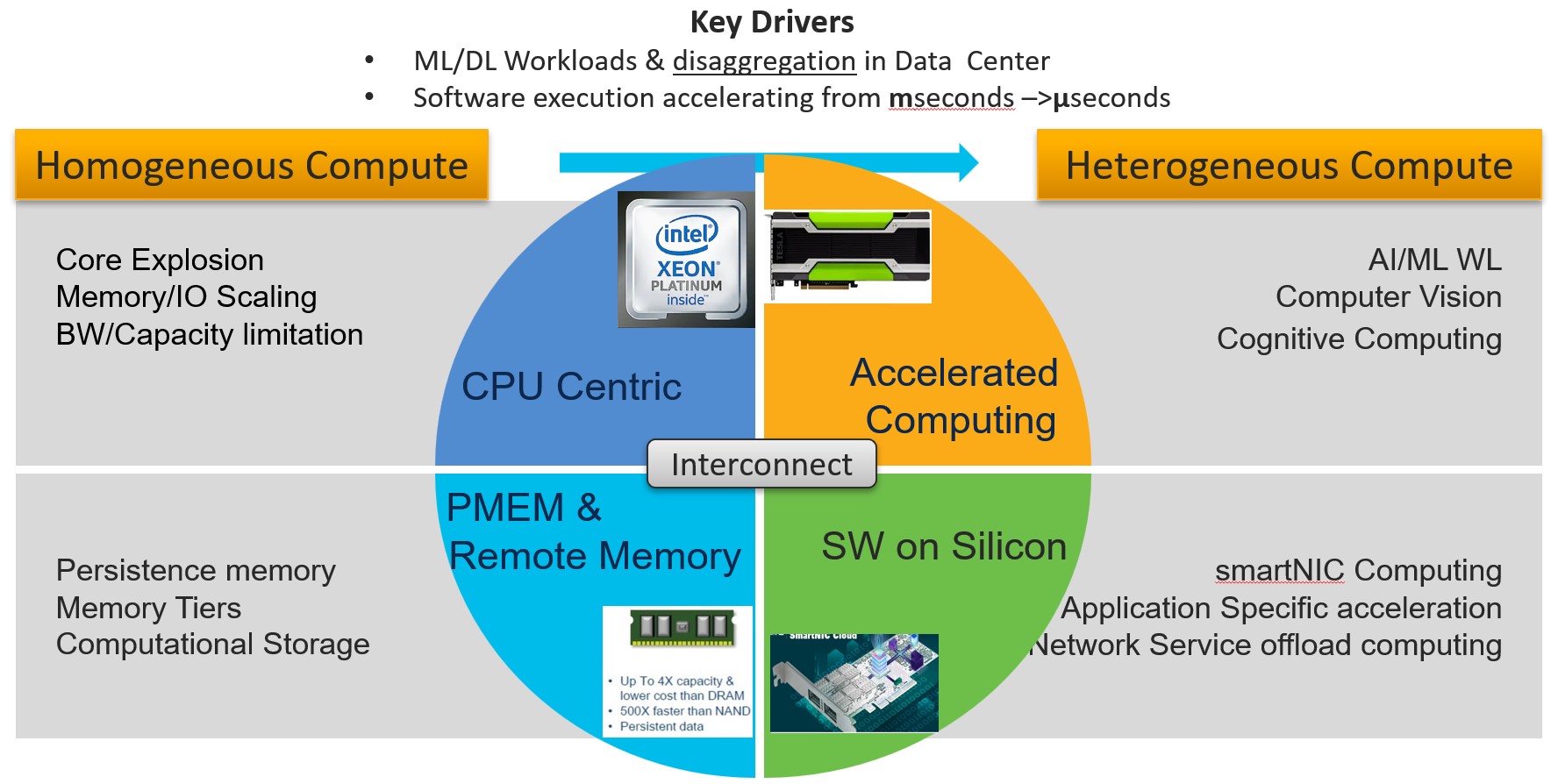
Heterogeneous computing brings the challenge of composability aspects of resources and IO interconnect that ties all these resources together. These resources can range from accelerated compute farms with specialized GPUs, sNIC computing subsystems and data processing at the edge of, or near storage -AKA computational storage. This compute everywhere model if not planned properly can result in wasted and replicated resources.
Entry level cost of accelerated computing such as GPU is very expensive. So, it is essential from TCO perspective to have resources that can be virtualized, composed and shared on demand. In essence new server architecture has to be dynamic and flexible where there are no captive resources & have ability to enable time shifted computing utilizing resources 24/7.
Additionally, peer to peer communication between resources for data movement bypasses central CPU eliminating need for redundant data copying . It helps in reduction of IO traffic on system bus and improves latency.
So, What IO fabric will tie heterogeneous subsystems together? A Single IO fabric approach may not be able to cater to the divergent needs off data center. A multi-fabric architecture approach is essential.
Ethernet is de-facto fabric in the data center for data ingestion into server from protocol aware IO/Storage traffic perspective. However, latency and coherency issues make it a poor choice at lowest tiers of Load/Store IO which usually happens in 10s of nS.
In order to fully realize the potential of heterogeneous computing new IO fabric must have
While PCIe IO technology filled the latency needs early on, it was slow to evolve from speeds and feature perspective as core explosion led to IO bandwidth issues. Several proprietary and open-source efforts were made to create a new IO interconnect. However, none of them found traction at scale until the emergence of CXL (Compute Express Link) Interconnect. While high bandwidth & Lo latency is paramount, it is the underlying protocol stack that needed overhaul for OS and applications to take advantage. CXL is based on the ubiquitous PCIe PHY layer and adds a efficient protocol stack that has a potential to enable subsystem and component level disaggregation in the data center.
Perhaps biggest impact on IO interconnect is coming due to the challenges in scaling memory bandwidth as core count increases.
The number of cores in processor is quadrupling from 32 to 128 and beyond in next couple of years. However, no of memory channels & bandwidth will scale @1.5 -2 x causing mismatch in the bandwidth per core. As core count grows beyond 128, incremental changes in memory channel speed will not be sufficient to maintain bandwidth/core ratio. To make matter worse, there will be spatial limitation beyond 12 channels per socket in standard rack form factor. To overcome all these limitations requires de-coupling of memory from CPU. Of course, de-coupling of memory requires order of magnitude more interconnect bandwidth. Scaling that much bandwidth and making memory multi-tenant will require a different IO transport than electrical domain. While we are still not there yet but in near future memory will become a network resource & with sNIC/DPU computing, network is indeed becoming computer.
UCX X-Series architecture is an amalgamation of new ideas, trends, and some bets in cohesive fashion to enable heterogeneous computing. It solves the existing needs and enables customers to adopt and extend hybrid cloud model as needed while balancing TCO.
In subsequent blogs, we will discuss about "The holy grail- case for memory disaggregation" and "Need for non-electrical IO transport" for memory disaggregation.
UCS X-Series -The Future of Computing Blog Series -Part 1 of 3
UCS X-Series -The Future of Computing Blog Series -Part 2 of 3
 Hot Tags :
Storage
#ciscodcc
Cisco UCS X-Series
heterogeneous infrastructure
disaggregated system
Accelerated Computing
smart NIC
Storage Class Memory
Heterogenous Computing
Hot Tags :
Storage
#ciscodcc
Cisco UCS X-Series
heterogeneous infrastructure
disaggregated system
Accelerated Computing
smart NIC
Storage Class Memory
Heterogenous Computing
Register Email now for Weekly Promotion Stock
100% free, Unsubscribe any time!
Add 1: Room 605 6/F FA YUEN Commercial Building, 75-77 FA YUEN Street, Mongkok KL, HongKong Add 2: Room 405, Building E, MeiDu Building, Gong Shu District, Hangzhou City, Zhejiang Province, China
Whatsapp/Tel: +8618057156223 Tel: 0086 571 86729517 Tel in HK: 00852 66181601
Email: [email protected]
 English
English Pусский
Pусский Français
Français Español
Español Português
Português

