Register now for better personalized quote!






























I've written about NUMA effects and process affinity on this blog lots of times in the past. It's a complex topic that has a lot of real-world affects on your MPI and HPC applications. If you're not using processor and memory affinity, you're likely experiencing performance degradation without even realizing it.
In short:
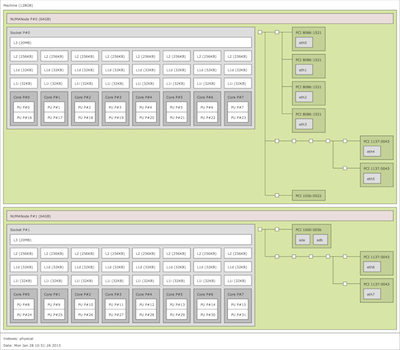 Intel Sandy Bridge-based server. Click to see the full-sized image.
Intel Sandy Bridge-based server. Click to see the full-sized image.Take the look at this hwloc-drawn schematic of the inside of a modern Intel "Sandy Bridge"-based server (click on it for the full-sized image). Notice a few things about it:
I mention these things because they all have distinct performance implications in an HPC application. Let's go through each of those points again, in order:
There are actually two performance effects from these three items. We already discussed how overall latency can be affected on each operation.
But don't forget thatnetwork congestionis another important performance effect.
"That's crazy talk!" you say. "We're talking about theinside of a single server. There's no network here!"
Not so, my friend. Don't forget what connects all the NUMA nodes and processor sockets together: QPI (or HyperTransport in AMD machines). That's a network. A full-blown, real network. With protocols, packets, and checksums. Oh my!
You can't completely eliminate the amount of traffic that is flowing across the NUMA-node-connecting-network, but you do want to minimize it. Networking 101 tells us that, in many cases, reducing congestion and contention on network links leads to overall better performance of the fabric. The same principle is true on networksinside a serveras it is for networksoutside of a server.
Using processor and memory affinity helps minimize all of the effects described above. Processes start and stay in a single location, and all the data they use in RAM tends to stay on the same NUMA node (thereby making it local). Caches aren't thrashed. Well-behaved MPI implementations use local NICs (when available). Less inter-NUMA-node traffic = more efficient computation.
With all that background, let's go back and address the two first points from this blog entry:
Use affinity. It's a Good Thing. And it's likely free and easy to enable in your MPI implementation / operating system already.
(Final note: the particular server shown in this example only has one processor socket per NUMA node. Things get even more... interesting... if there are multiple sockets per NUMA node.)
 Hot Tags :
HPC
mpi
process affinity
NUMA
hwloc
Hot Tags :
HPC
mpi
process affinity
NUMA
hwloc
Register Email now for Weekly Promotion Stock
100% free, Unsubscribe any time!
Add 1: Room 605 6/F FA YUEN Commercial Building, 75-77 FA YUEN Street, Mongkok KL, HongKong Add 2: Room 405, Building E, MeiDu Building, Gong Shu District, Hangzhou City, Zhejiang Province, China
Whatsapp/Tel: +8618057156223 Tel: 0086 571 86729517 Tel in HK: 00852 66181601
Email: [email protected]
 English
English Pусский
Pусский Français
Français Español
Español Português
Português

