Register now for better personalized quote!






























![]()
Following part one of our Big Data in Security series on TRAC tools, I caught up with talented data scientist Mahdi Namazifar to discuss TRAC's work with the Berkeley AMPLab Big Data stack.
Researchers at University of California, Berkeley AMPLab built this open source Berkeley Data Analytics Stack (BDAS), starting at the bottom what is Mesos?
AMPLab is looking at the big data problem from a slightly different perspective, a novel perspective that includes a number of different components.When you look at the stack at the lowest level, you see Mesos, which is a resource management tool for cluster computing. Suppose you have a cluster that you are using for running Hadoop Map Reduce jobs, MPI jobs, and multi-threaded jobs. Mesos manages the available computing resources and assigns them to different kinds of jobs running on the cluster in an efficient way. In a traditional Hadoop cluster, only one Map-Reduce job is running at any given time and that job blocks all the cluster resources. Mesos on the other hand, sits on top of a cluster and manages the resources for all the different types of computation that might be running on the cluster. Mesos is similar to Apache YARN, which is another cluster resource management tool. TRAC doesn't currently use Mesos.
 The AMPLab Statck
The AMPLab Statck
You mentioned that this stack is novel, how so?
The layer that excites us the most is Spark, which is the stack's Map-Reduce engine. The innovative idea behind Spark is the concept of Resilient Distributed Datasets (RDD). For the purpose of fault tolerance, Hadoop Map-Reduce uses redundancy in the sense that after every stage of a Map-Reduce job, multiple copies of the intermediate results are written to disk on different nodes, so that in the case of losing a process or a node, the part of the job that was lost may be restarted from the last finished stage. This writing to and reading from disk at each stage of a job significantly slows down the whole process. In Spark, on the other hand, the concept of redundancy for fault tolerance is replaced by the concept of RDD. For the purpose of fault tolerance, for each RDD, which is, in principle, a slice of a data set, Spark keeps the lineage of the RDD. So for each RDD, Spark remembers how it was built and the set of transformations that happened on the data to make that RDD. In the event that a specific RDD is lost (using the lineage of the lost RDD), Spark can rebuild the RDD from scratch. As you can see this scenario is not disk I/O intensive like Hadoop Map-Reduce.
Spark is also novel in the way it performs Map-Reduce job execution planning. If job stages can be combined into one stage, Spark automatically plans the execution of the job accordingly. This kind of optimization in Spark Map-Reduce makes it significantly faster than Hadoop Map-Reduce.
Spark is feature rich, and one of its most interesting capabilities is the in-memory computation. You can load an entire RDD or parts of it into memory in a distributed manner over the cluster and subsequently use this cached data for computation and, therefore, receive significant time savings. Using the cached data instead of reading the data from disk could result in two orders of magnitude faster computations.
Shark is another innovative BDAS element that we evaluated. Shark provides a SQL API for Spark, which is the equivalent of Hive for Hadoop Map-Reduce, but more optimized and with in-memory options. Shark's advantages over other tools like Hive come from the use of optimizations such as Partial DAG Execution (PDE), map pruning, and in-memory capabilities.
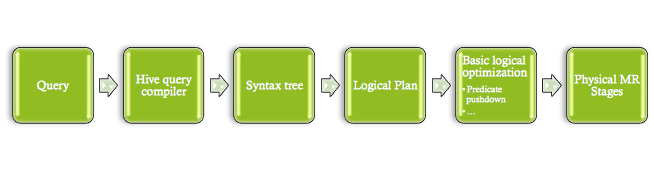 Hive query execution path
Hive query execution path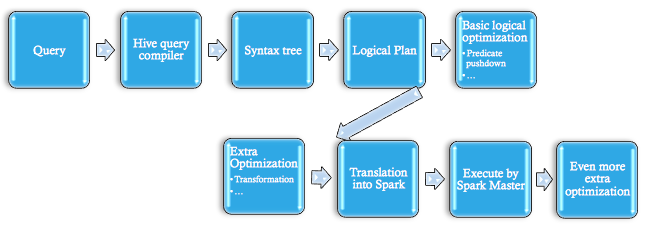 Shark query execution path
Shark query execution path
Why did TRAC decide to use Spark?
In order for large volumes of data to be useful we need to be able to understand the data by playing with it, massaging it, summarizing it, and we also need to extract predictive signals out of the data. Spark provides a combination of great facilities for performing pretty much every kind of process on the data that you want in an easy and relatively efficient way. Spark is easy to use and it has APIs for Scala, Java, and Python. For example, writing a word count code for a set of text files using Spark's Scala API is as easy as the following line:
val c = sc.textFile(<your files>).flatMap(x => x.split(" ")).map(x => (x,1)).reduceByKey(_+_)
Similar functionality in Java Hadoop Map-Reduce would literally require over one hundred lines of code. Looking at the other options for Map-Reduce programming, we find Spark to be one of the most powerful tools in terms of performance, flexibility, ease of use, ease of integration with other languages, and, of course, the in-memory capabilities. Pig, which is one of the most popular Map-Reduce languages for Hadoop, is another option and a great tool, but it lacks many Spark advantages.
More flexible resource management on the cluster is also a strong Spark feature. When you run a traditional Hadoop Map-Reduce job on your data (residing on HDFS), the job basically takes over the entire cluster and uses all of the cluster resources, thus you have a single jobs queue. With Spark, you can specify how many resources (CPU and memory) you want for each job and as a result, multiple jobs may be run simultaneously on the cluster.
We also significantly benefit from Spark's in-memory capabilities. The other Map Reduce tools don't provide this option. Especially for iterative processes like machine learning algorithms, this in-memory capability becomes very handy. As larger amounts of memory are available, it becomes desirable to perform data computations in memory as opposed to hard disk. The demand for in-memory tools capable of handling Big Data continues to grow, and thus far, Spark is leading the pack.
Spark also provides an interactive Scala based interface, which is a command line environment similar to a Scala shell. This, along with the in-memory capabilities, makes Spark a superb tool for real time Big Data analysis. Also, starting a Spark Map-Reduce job has pretty much zero initialization overhead, which is great compared to Hadoop Map-Reduce, in which initialization of a job could take up to several seconds. Scala based Map-Reduce languages such as Spark, Scoobi, Scrunch, and Scalding are very popular these days among data science professionals due to their superiorities. We use Spark due to its comparative advantages including in-memory features.
At the top of the AMPLab stack is BlinkDB, what is it?
BlinkDB is a SQL query engine that runs queries on massive data sets (terabytes or even petabytes), in an approximate fashion, in a matter of seconds or even sub-seconds. BlinkDB accomplishes this feat through sampling. The goal is to understand the kinds of queries that are regularly run on the data and then create several different stratified samples of the data that capture those queries and different confidence interval for the queries. The user can specify the confidence level (for example 95 percent) and/or the maximum time that the query could take (for example two seconds) and then BlinkDB selects the right sample and runs the query on it. These samples are taken to address different queries with different confidence intervals and different time frames, and they are taken offline.
The first release of BlinkDB came out about three months ago. The tool is still quite young and is missing some of the features that were described in the BlinkDB paper. We are excited about the upcoming releases of BlinkDB and we are investigating the current release to assess how we can benefit from BlinkDB's capabilities.
 BlinkDB -Obtain super-fast query results in exchange for a small percentage of error.
BlinkDB -Obtain super-fast query results in exchange for a small percentage of error.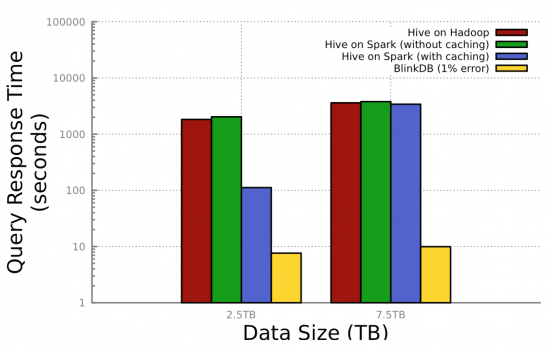
For TRAC, what are some of the potential BlinkDB use cases?
It's useful in threat analysis where the data set is large and we need to get an understanding of the data without spending too much time on it. We can quickly answer questions like: what are the different fields? How are they populated? What are the anomalies?
So is TRAC building a hybrid stack that includes AMPLab components to address different TRAC use cases?
Absolutely, we have investigated a wide variety of tools at every layer of the data analytics stack. At this point we have solidified our stack choices, for example as I mentioned earlier, Spark is our choice for some of our Map-Reduce needs related to ad-hoc investigative work.
You have done a lot of testing, analysis, and bench marking to compile this custom stack, are you confident at this point that this is the best solution to accomplish Cisco's current and future security analysis goals?
We are confident to a point because Big Data is a very dynamic area, every other week we hear about a new tool. You cannot ever be absolutely confident about one solution because there may be a game changing tool that is announced tomorrow. Moreover, for Big Data problems there is no notion of "THE solution," and different solutions should be considered in the appropriate context and for a specific set of use cases. We do stay on top of emerging technologies and new research and we do continually refine our stack. We have invested a lot of resources at every layer of this stack and if we snapshot the situation today we are fully confident in our solution.
That concludes today's Big Data in Security conversation. Mahdi's additional AMPLab Stack comments can be heard on TRAC Fahrenheit: cs.co/6011dHBT. Catch up on yesterday's TRAC Tools blog, and don't miss tomorrow's Q&A when I speak with Michael Howe and Preetham Raghunanda about their exciting graph analytics work.
 Mahdi Namazifar joined TRAC in January 2013. Prior to Cisco, he was a Scientist at Opera Solutions where he worked on a variety of data analytics and machine learning problems from industries such as finance and healthcare. He received a master's degree in 2008 and a PhD in 2011 in operations research from the University of Wisconsin-Madison. During his time as a PhD student, Mahdi did internships at IBM T.J. Watson Research Lab and the San Diego Supercomputer Center. Mahdi's research interests include machine learning, mathematical optimization, parallel computing, and Big Data.
Mahdi Namazifar joined TRAC in January 2013. Prior to Cisco, he was a Scientist at Opera Solutions where he worked on a variety of data analytics and machine learning problems from industries such as finance and healthcare. He received a master's degree in 2008 and a PhD in 2011 in operations research from the University of Wisconsin-Madison. During his time as a PhD student, Mahdi did internships at IBM T.J. Watson Research Lab and the San Diego Supercomputer Center. Mahdi's research interests include machine learning, mathematical optimization, parallel computing, and Big Data.
 Hot Tags :
Big Data
#Security
Analytics
Hadoop
database
custom
BlinkDB
AMPLab
BDAS
Hot Tags :
Big Data
#Security
Analytics
Hadoop
database
custom
BlinkDB
AMPLab
BDAS
Register Email now for Weekly Promotion Stock
100% free, Unsubscribe any time!
Add 1: Room 605 6/F FA YUEN Commercial Building, 75-77 FA YUEN Street, Mongkok KL, HongKong Add 2: Room 405, Building E, MeiDu Building, Gong Shu District, Hangzhou City, Zhejiang Province, China
Whatsapp/Tel: +8618057156223 Tel: 0086 571 86729517 Tel in HK: 00852 66181601
Email: [email protected]
 English
English Pусский
Pусский Français
Français Español
Español Português
Português

