Register now for better personalized quote!






























 This is a two-part blog series developed in association with Tom Edsall, a Cisco Fellow and CTO of Insieme Networks, recently acquired by Cisco Systems. The intent is to elaborate on foundational design principles of Application Centric Infrastructure (ACI), a transformational approach for next-generation and cloud deployments. While the vision of ACI is an expansive one, this blog series focuses on the role of SDN overlays, their deployment considerations, as well as benefits that customers could derive from the unique implementation of overlays in an ACI solution.
This is a two-part blog series developed in association with Tom Edsall, a Cisco Fellow and CTO of Insieme Networks, recently acquired by Cisco Systems. The intent is to elaborate on foundational design principles of Application Centric Infrastructure (ACI), a transformational approach for next-generation and cloud deployments. While the vision of ACI is an expansive one, this blog series focuses on the role of SDN overlays, their deployment considerations, as well as benefits that customers could derive from the unique implementation of overlays in an ACI solution.
Cisco's Application Centric Infrastructure approach focuses on the most important thing in the data-center: applications. Without applications, we would not even need a data center at all! Everything we do in the data center ultimately is used to support those applications and the data that they work on because that is what ultimately drives business value.
The modern data center must be able to deploy applications rapidly, using any and all resources (compute, storage, network) available in the data center at any time. It must also be possible to grow, shrink, and move applications as needed. This will drive business agility and efficient use of resources.
The problem is that classical networking systems were developed in a world where there was less focus on any application anywhere, any time. Instead the focus was on on building large, static, IP networks.
Our solution was to create an application centric infrastructure where the emphasis is on the application rather than on the network. In order to do this we had to change the abstraction of the network from one that is, well, network centric to one that is application centric. In addition, we had to employ some SDN techniques to change the network from a traditional static infrastructure to a more dynamic, agile, flexible infrastructure. Let's look into some of these techniques in detail.
We employ two important concepts used in typical SDN solutions: overlays and a centralized controller. Overlays give us network flexibility that was never possible before by separating the location of a device from its identity. The centralized controller gives us consistent network behavior wherever an application is deployed, the application centric abstraction of the network, and a single point of control. While these benefits are important, even fundamental, to building a data center capable of supporting the business requirements of application agility, they also introduce their own set of problems in traditional SDN deployments that must be addressed. We will discuss these issues and their solutions shortly.
The SDN overlay and application abstraction is built on top of networking hardware that must move data across the data center quickly and efficiently without requiring changes to the applications, servers or storage elements attached to it. The hardware must do this in an efficient, reliable manner and provide as much assistance as possible to the network operator when troubleshooting and monitoring those applications as they use the network. Lastly, this hardware must be cost effective, power efficient, and space efficient.
Network overlays are a technique used in state-of-the-art data centers to create a flexible infrastructure over an inherently static network by virtualizing the network. Before going into the details of how overlays work, the challenges they face, and the solutions to those problems, we should spend a little time understanding better why traditional networks are so static.
When networks were first developed there was no such thing as an application moving from one place to another while it was in use. So the original architects of IP, the communication protocol used between computers, used the IP address to mean both the identity of a device connected to the network and its location on the network. This was a perfectly reasonable thing to do since computers and their applications did not move, or at least they did not move very fast or very often. Since then all of our applications and networks have been built with this simple assumption that the IP address can be used as both the identity of the device being communicated with and its location.
Today in the modern data center, we need to be able to communicate with an application, or application tier, no matter where it is. One day it may be in location A and the next in location B, but its identity which we communicate with, is the same on both days. We want to be able to send a message from one application to another independent of where those applications are. Somehow we need to separate the location of the application on the network and its identity so that we can change the location at will. This is where overlays come into the picture.
An overlay is when we take the original message sent by an application and encapsulate with the location it needs to be delivered to before sending it through the network. Once it arrives at its final destination, we unwrap it and deliver the original message as desired. The identities of the devices (applications) communicating are in the original message and the locations are in the encapsulation thus separating the location from the identity. This wrapping and unwrapping is done on a per packet basis and therefore must be done very quickly and efficiently.
Let's take a simple example to illustrate how this is done. Imagine that application App-A wants to send a packet to App-B. App-A is located on a server attached to switch S1 and App-B is initially located on switch S2. When App-A creates the message, it will put App-B as the destination and then send the message to the network. When the message is received at the edge of the network, whether that is a virtual edge in a hypervisor or a physical edge in a switch, the network will look up in a "mapping" database the location of App-B and see that it is attached to switch S2. It will then put the address of S2 on the outside of the original message. We now have a new message that is addressed to switch S2. The network will then forward this new message to S2 using traditional networking mechanisms. Note that the location of S2 is very static, i.e. it does not move, so using traditional mechanisms works just fine.
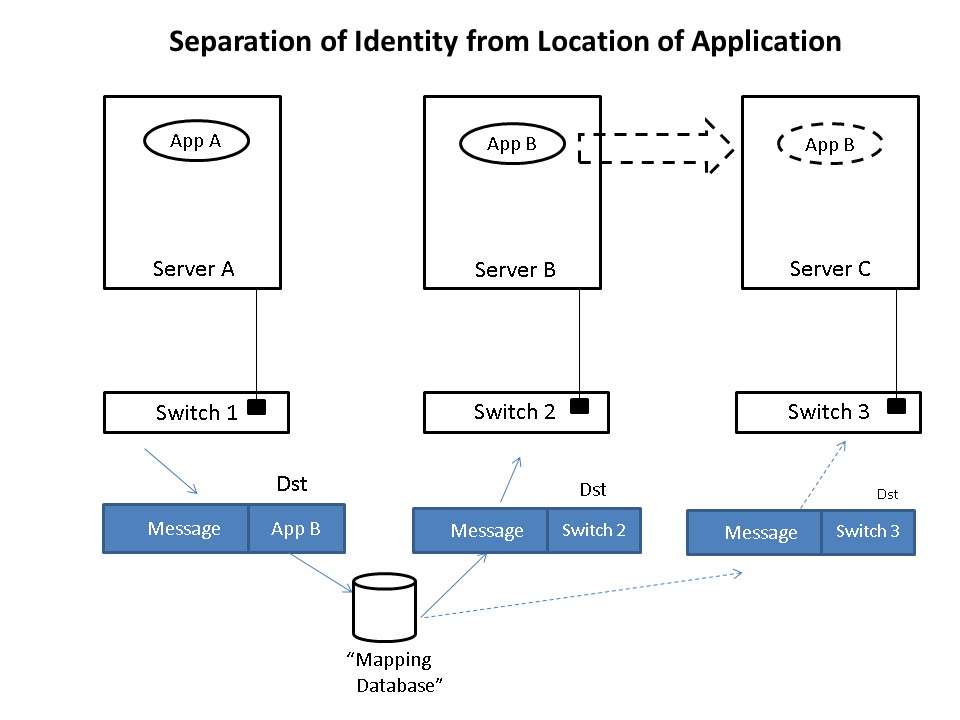
Upon receiving the new message, S2 will remove the outer address and thus recover the original message. Since App-B is directly connected to S2, it can then forward the message to App-B easily. Note that App-A never had to know where App-B was located nor did the core of the network. Only the edge of the network and specifically only the mapping data base had to know the location of App-B. The rest of the network only had to know the location of switch S2, which does not change.
Lets now assume App-B moves to a new location, switch S3. Now when App-A sends a message to App-B, it does exactly the same thing it did before, i.e. it addresses the message to App-B and gives the packet to the network. The network then looks up the location of App-B and finds that it is now attached to switch S3. It puts S3's address on the message and forwards it accordingly. At S3, the message is received, the outer address removed, and the original message delivered as desired.
The movement of App-B was not tracked by App-A at all. In fact the address of App-B identified App-B while the address of the switch, S2 or S3, identified App-B's location. App-A is able to communicate freely with App-B no matter where App-B is located which allows the system administrator to place App-B in any location and move it as desired thus achieving the flexibility needed in the data center.
When implementing an overlay there are 3 major tasks that have to be accomplished and they were all used in the example. First, there must be a mechanism to forward packets through the network. Traditional networking mechanisms work fine for this.
Second, there must be a mapping database where the location of a device or application can be lookup up and the result used to encapsulate the packet. This can be done in hardware or software, but should have good performance as it is done for every packet sent across the network.
Third, there must be a way to update the mapping database such that it is always as accurate as possible. Having the wrong information in the mapping database would result in packets being sent to the wrong location and likely dropped. This is as bad, or even worse, than not forwarding the packet in the first place.
The first task, forwarding the packet, is something that networking equipment has done well for a long time and it is not a big problem today. However, as much attention to performance, cost, reliability, operations, and support must be applied to this network carrying the overlay as there always has been to networks in the data center.
The second task -mapping lookup and encapsulation -is really an issue of performance and capability. If we were to do the mapping lookup and encapsulation in software, it would take some CPU performance away from the applications themselves and will add some latency when compared to hardware solutions. Furthermore, assuming there is a desire to do it in hypervisor software running on the server there isn't always a good place to do it. If the server is not virtualized, i.e. is "bare metal" with no hypervisor, the encapsulation will have to be done either in hardware or by a software entity located elsewhere. Again, software here will add latency and consume CPU cycles that might be better used for executing applications.
The "bare metal" problem is actually bigger than most assume. While the number of workloads that are virtualized is 60-70% of all workloads and growing, more than 80% of the servers in use today arenotrunning virtualized workloads. This may, at first, seem contradictory, but a simple illustration will show that it is not. Imagine that you have a server that is running 10 virtual machines or virtual workloads. To get the total number of virtual workloads to be 70% of the total workloads, you would then have to run 4 additional workloads on bare metal servers for a total of 14 workloads. In this reasonable scenario, you have 10 out of 14 workloads virtualized, i.e. about 70%, and 4 out of 5 servers are bare metal, i.e. 80%.
Of course every environment and every data center is unique and the mix of servers running virtualized workloads vs. non-virtualized workloads covers the entire spectrum. However, the feedback we get from nearly all of our customers is that they have a mix, whether they like it or not, and any solution for the data center must address this mix.
The third component of an overlay is how modifications to the mapping database are synchronized across all places where it is kept. This is a real challenge and a concern for any data center administrator. Furthermore, how the solution to this problem can be evaluated is challenging because problems here happen when scaling the system in the presence of errors, which is particularly difficult to replicate in a proof-of-concept lab (POC).
To get an appreciation of this problem, imagine that we implement the mapping database in software in each server of the data center. If there are 1000 servers, then 1000 locations need to be updated in a consistent manner whenever an application moves or a virtual machine instance is brought on-line. There is always the chance that at not all of those servers will get the mapping update. It may work 99% of the time, but 99% is not good enough. With an average of 10 VMs per server, there are 10,000 VMs in this data center. If each one moves once a month, there will be 120,000 moves a year. If 1% of those moves results in a single update failure, we have 1200 potential application issues each year due to the overlay alone. Furthermore, debugging these issues will likely be particularly difficult given the lack of visibility between the physical infrastructure and the overlay (more on this later).
Let analyze this problem more deeply. When scaling a distributed overlay mapping database there are several factors to consider-
The first three items are pretty obvious. If we don't have to update the state very often, it is easier to scale. Unfortunately, we cannot control the rate of change in the data center. When an application or service needs to move, it just needs to move. If anything, the rate of change is increasing as it becomes easier to move an application and as data centers optimize the placement of applications more and more in real-time. Also, the number of changes would increase as the number of virtual machines in the data center increases.
The above considerations are summarized here:
Part 2will cover the benefits of Overlay Integration in ACI deployments. For more information on Cisco approach to Application Centric Infrastructure, please visit www.cisco.com/go/aci
 Hot Tags :
Cisco ACI
Cisco Application Centric Infrastructure (ACI)
VXLAN
Shashi Kiran
SDN Overlays
Tom Edsall
Hot Tags :
Cisco ACI
Cisco Application Centric Infrastructure (ACI)
VXLAN
Shashi Kiran
SDN Overlays
Tom Edsall
Register Email now for Weekly Promotion Stock
100% free, Unsubscribe any time!
Add 1: Room 605 6/F FA YUEN Commercial Building, 75-77 FA YUEN Street, Mongkok KL, HongKong Add 2: Room 405, Building E, MeiDu Building, Gong Shu District, Hangzhou City, Zhejiang Province, China
Whatsapp/Tel: +8618057156223 Tel: 0086 571 86729517 Tel in HK: 00852 66181601
Email: [email protected]
 English
English Pусский
Pусский Français
Français Español
Español Português
Português

