Register now for better personalized quote!






























This|blog|is co-authored by Alex Huang, Cisco Senior Machine Learning Engineer
Speaker Diarization answers the question, "Who spoke when?" Currently, speakers in a meeting are identified through channel endpoints whether through PSTN or VOIP. When speakers in the same meeting are speaking from the same room/device, they are identified as one speaker in the meeting transcript. Because Webex Meetings recordings are provided with transcriptions, being able to answer "Who spoke when?" would allow colleagues who might have missed the meeting to quickly catch up with what was said as well as provide automatic highlights and summaries. This is very useful, but without knowing who said what, it is more difficult for humans to skim through the content, and for AI solutions to provide more accurate results.
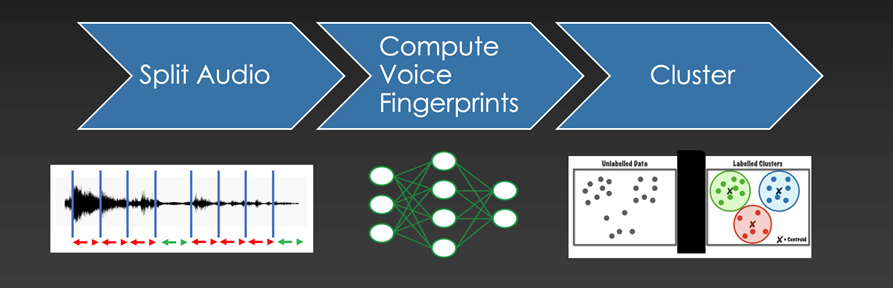 Assigning speaker labels to an audio file can be divided into 3 steps
Assigning speaker labels to an audio file can be divided into 3 steps
The process to assign speaker labels to an audio file is straightfoward and can be divided into 3 steps:
The goal and the features
We do not want to restrict the quality of the diarization based on language, accent, gender or age because meetings can occur in varied settings with different microphones and background noises. We designed the neural network responsible to compute the voice fingerprints to be robust to these factors. This is made possible by choosing the proper neural architecture, a vast amount of training data, and data augmentation techniques.
The architecture
The architecture of the neural network can be split into 2 parts: preprocessing and feature extraction. The preprocessing part transforms the 1-dimensional audio input into a 2-dimensional representation. The standard approach is to compute the Spectrogram or the Mel-frequency cepstral coefficients (MFCCs). Our approach is to let the neural network learn this transformation as a sequence of 3 1-D convolutions. The reasoning behind this choice is twofold. First off, given enough data, our hope is that the transformation will be of higher quality for the downstream task. The second reason is practical. We export the network to the ONNX format in order to speed up inference and as of now the operations needed to compute the MFCCs are not supported.
For the feature extraction we rely on a common neural network architecture commonly used for Computer Vision tasks: ResNet18. We modified the standard architecture to improve performance and to increase inference speed.
The goal of this step is to assign a label to each audio segment so that audio segments from the same speaker gets assigned the same label. Grouping together is done by feature similarity and is easier said than done. For example: given a pile of Lego Blocks how would we group them? It could be by color, by shape, by size, etc... Furthermore, the objects we want to group could even have features that are not easily recognizable. For our use case, we are trying to group together 256-dimensional vectors, in other words "objects" with 256 features, and we are counting on the neural network responsible for producing these vectors to do a good job. At the core of each clustering algorithm there is a way to measure how similar two objects are. For our case we measure the angle between a pair of vectors: cosine similarity. The choice of this measurement is not random but is a consequence of how the neural network is trained.
Online clusteringmeans that we assign a speaker label to a vector in real time as an audio chunk gets processed. On one hand, we get a result right away and this can be useful for live captioning use cases for example. On the other hand, we can't go back in time and correct labeling mistakes. If the generated voice fingerprints are of high quality, the results are usually good. We employee a straightforward greedy algorithm: as a new vector gets processed, we assign it to a new or an existing bucket (collection of vectors). This is done by measuring how similar the new vector is to the average vector in each bucket. If it is similar enough (based on a selected similarity threshold), the vector will be added to the most similar bucket. Otherwise, it will be assigned a new bucket.
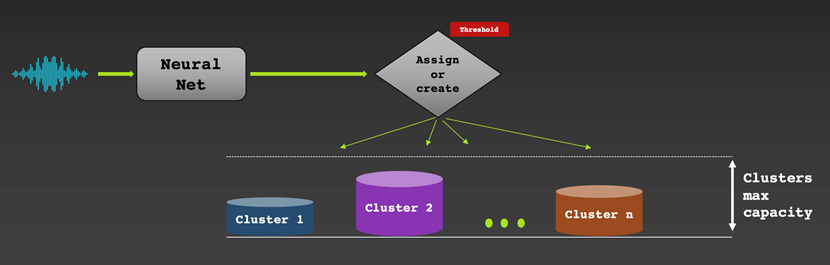
Offline clusteringmeans that we assign a speaker label to each vector after we have access to the entire audio. This allows the algorithm to go back and forth in time to find the best speaker label assignment, typically outperforming online clustering methods. The downside is that we need to wait for the full audio recording to be available which makes this technique not suitable for real-time transcriptions. We base our approach on Spectral Clustering. Without going into too much detail, since this is a common technique, we chose this particular method because it's robust for the particular data we have. More importantly, it is able to estimate the number of speakers automatically. This is an important feature since we are not given the number of speaker/clusters beforehand.
The backbone of the neural audio embedder and the clustering algorithm described above is the data used to train it and thankfully we're in a great situation in that regard. We work closely on diarization with the Voicea team within Cisco, who are responsible for handling meeting transcription in Webex. During that process, they save audio segments from meetings that they detect speech in and make them available for download. Each saved segment is automatically labeled according to the device it comes. This allows us to use these audio segments to train our speaker embedder on a speaker recognition task. Due to the high volume of meetings that are hosted on WebEx we're able to collect a great deal of data and the amount continues to increase over time.
One package that helps us collaborate efficiently while working with this quantity of data is DVC, short for Data Version Control. DVC is an open-source tool for version control on datasets and models that are too large to track using git. When you add a file or folder to DVC, it creates a small .dvc file that tracks the original through future changes and uploads the original content to cloud storage. Changing the original file produces a new version of the .dvc file and going to older versions of the .dvc file will allow you to revert to older versions of the tracked file. We add this .dvc file to git because we can then easily switch to older versions of it and pull past versions of the tracked file from the cloud. This can be very useful in ML projects if you want to switch to older versions of datasets or identify which dataset the model was trained on.
Another benefit of DVC is functionality for sharing models and datasets. Each time one person collects data from the Voicea endpoint to add to the speaker recognition dataset, as long as that person updates the .dvc file and pushes it, the other person can seamlessly download the new data from the cloud and start training on it. The same process applies for sharing new models as well.
The first WebEx integration for our diarization model was on the meeting recordings page. This page is where people can see a replay of a recorded meeting along with transcriptions provided by Voicea. Our diarization is integrated within Voicea's meeting transcription pipeline and runs alongside it after the meeting is finished and the recording is saved. What we add to their system is a speaker label to each audio shard that Voicea identifies and segments. The goal for our system is that if we give one audio shard a label of X, the same speaker producing an audio shard later in the meeting will also receive a label of X.
There were significant efforts dedicated to improving runtime of the diarization so that it fit within an acceptable range. The biggest impact was changing the clustering to work when splitting up a meeting into smaller chunks. Because we run eigendecomposition during the spectral clustering, the runtime is O(n^3) in practice, which results in extended runtimes and memory issues for long meetings. By splitting the meeting into 20-minute chunks, running diarization on each part separately, and recombining the results, we have a slight accuracy trade off for huge reductions in runtime.
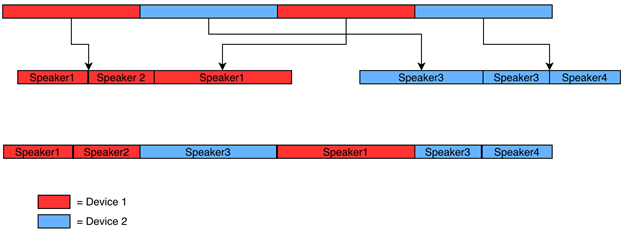
The other integration with WebEx is diarization for the post-meeting page. This page is shown directly after a meeting and contains transcription information as well. The main difference from the previous integration is that we have information on which device each audio segment comes from. What this means is that we can do diarization separately for each audio endpoint and avoid errors where our model predicts the same speaker for audio that came from different devices.
This diagram shows how this works in practice. The red segments are from device 1, the blue segments are from device 2, and there are 2 speakers in each device. We first group up all the audio from each device and run the diarization separately for each group. This gives us timestamps and speaker labels within each single device grouping. We keep track of the time offset of each segment as it is grouped by device and use that to transform the speaker label times from the device grouping to what they are in the original, full meeting.
The post-meeting integration is also deployed within the Voicea infrastructure on Kubernetes. Our service is deployed as a Flask app within a docker image that interfaces with several other micro services.
What you can build with a good Neural Voice Embedder doesn't stop with Speaker Diarization.
If you have some name-labelled audio samples from speakers that are present in the meetings you want to diarize, you could go one step further and provide the correct name for each segment.
Similarly, you could build a voice authentication/verification app by comparing an audio input with a database of labelled audio segments.
We wanted to make it easy for developers to get their hands dirty and quickly build solutions around the speaker diarization and recognition domain. Project vo-id (Voice Identification) is an open-source project structured to let developers with different expertise in AI to do so. The README cointains all the information needed. To give you an example, it takes only 4 lines of code to perform speaker diarization on an audio file:
audio_path ="tests/audio_samples/short_podcast.wav"fromvoid.voicetoolsimport ToolBox#Leave `use_cpu` blank to let the machine use the GPU if availabletb =ToolBox(use_cpu=True) rttm = tb.diarize(audio_path)
We provided a trained neural network (the vectorizer), but if you have the resources, we made it possible to update and train the neural network yourself: all the information needed is available in the README.
We'd love to hear what you think. Ask a question or leave a comment below.
And stay connected with Cisco DevNet on social!
Twitter @CiscoDevNet | Facebook | LinkedIn
Visit the new Developer Video Channel
 Hot Tags :
Cisco DevNet
Speaker Diarization
Hot Tags :
Cisco DevNet
Speaker Diarization
Register Email now for Weekly Promotion Stock
100% free, Unsubscribe any time!
Add 1: Room 605 6/F FA YUEN Commercial Building, 75-77 FA YUEN Street, Mongkok KL, HongKong Add 2: Room 405, Building E, MeiDu Building, Gong Shu District, Hangzhou City, Zhejiang Province, China
Whatsapp/Tel: +8618057156223 Tel: 0086 571 86729517 Tel in HK: 00852 66181601
Email: [email protected]
 English
English Pусский
Pусский Français
Français Español
Español Português
Português

