Register now for better personalized quote!






























The cloud native universe has experienced an explosion of innovation with a velocity and richness of capabilities that would've been hard to imagine a decade ago. The next frontier of innovation for cloud providers is being built on machine learning and artificial intelligence (ML/AI). These emerging capabilities offer customers real-time insight and increase the value and stickiness of the cloud's services. In contrast, networking has lagged. While speeds and feeds have enjoyed Moore's Law-like exponential growth, there hasn't been a corresponding explosion in-network service innovation (much less a leap toward ML/AI-driven services and operations).
Simply put, ML/AI is built on a foundation of automation, with the evolution to fully autonomous networks being a journey through multiple levels (see: TMForum report on the 5 levels of autonomous networks). As our colleague Emerson Moura highlights in his network simplification blog as part of this series, the traditional stacking of network technologies has led to an overly complex, heterogeneous environment that's very difficult to automate end to end. This heterogeneity leads to a sort of rigidity at the business level, where automation and new service innovation is enormously difficult and time-consuming.
From the perspective of customers or end-users, the network is a mysterious black box. When a customer's technology or applications aren't behaving as expected, the network often becomes a target of finger-pointing. When customers, application owners, and end-users lack visibility and control over the fate of their traffic, they all too often perceive the network as a problem to be worked around rather than an asset to be worked with.
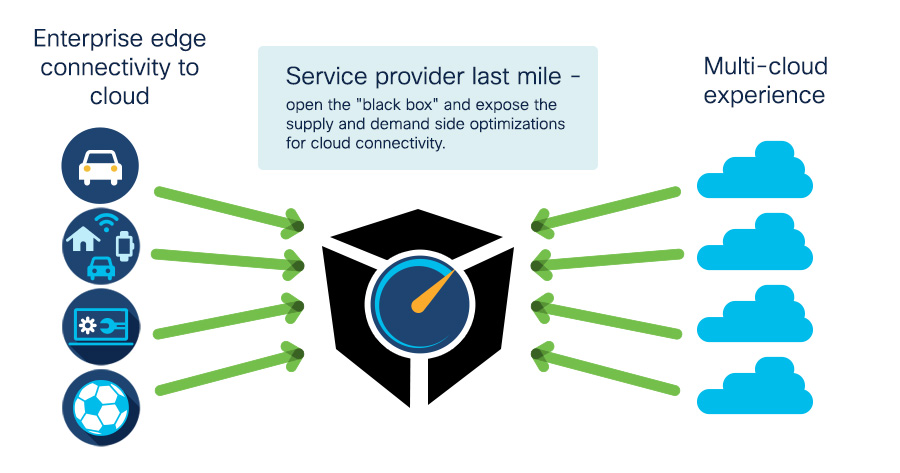
When we say 'workarounds' that often means the customer moves their traffic over the top. In the process, the transport network is commoditized, and innovation moves elsewhere.
A future service provider network will realize significant benefits if its highly automated services and operations are augmented with ML/AI capabilities. We can envision an autonomous network that is able to use ML/AI to be self-healing, self-optimizing, proactive, and predictive.
Telemetry analytics systems will have trained up on historical failure conditions, error or outage notifications, or other indications of a problem, and will have run thousands of failure and repair simulations (see: principles of chaos). With these datasets, the network ML/AI will be able to auto-remediate a very large percentage of problems, often before they become service-affecting. Facebook's FBAR and LinkedIn's Nurse are examples of such systems in use today. For further reading, check out JP Vasseur's whitepaper: Towards a Predictive Internet.
In addition to auto-remediation or taking proactive action, we can expect ML/AI-driven network control systems to self-optimize the network. This could be as simple as using per-flow SRTE to move lower priority flows away from high value or congested links. Or, if the operator has implemented a cloud-like, demand-driven networking model outlined in our blog post "Evolved Connectivity", the operator could take a market-based approach to self-optimization. In other words, the ML/AI system could introduce pricing incentives (or disincentives) wherein the subscribing customer can choose between a highly utilized, and therefore high price path versus a less utilized, lower price path. Traffic may take longer to traverse the lower price path, but that might be perfectly acceptable for some traffic if the price is right. It's essentially airline seating-class pricing using segment routing! The operator gets cloud-like utilization revenue, more optimal usage of existing network capacity, and more predictable capacity planning, while the customer gets a custom-tailored transport service on demand.
To get to an ML/AI-driven network there are a few fundamental principles that need to be followed, as described below.
The first rule in automation should be "reduce the number of different elements or variables you need to automate." In other words, ruthlessly standardize end to end and weed out complexity and/or heterogeneity. To quote the TMForum paper referenced earlier: "Making the leap from traditional manual telco operations to AN (autonomous networking) requires CSPs to abandon the idea of islands of functionality and adopt a more end-to-end approach."
The fewer unique systems, features, knobs, or other touchpoints, the less effort it takes to create, and perhaps more importantly to maintain automation. Cloud operators have standardized the lower levels of their stack: the hardware, operating systems, hypervisors, container orchestration systems, and interfaces into those layers. This lower-layer homogeneity makes it much easier to innovate further up the stack. We recommend adopting a common end-to-end forwarding architecture (totally unsubtle hint: SRv6) and set of management interfaces, which will allow the operator to spend less time and energy on automation and complex integrations and put more effort into developing new products and services. The simpler and more standardized the infrastructure layers, the more time we can spend innovating in the layers above.
Cloud operators collect massive amounts of data and feed it through scaled analytics engines in an ongoing cycle of improvement and innovation. The networking industry needs to think more broadly about data collection and analysis. Ideally, we would collect data and model our digital transport networks the way Google Maps collects data and models human transportation networks.
Our Google-Maps-For-Networks should be massively scalable, and we should expand the meaning of network telemetry data to go well beyond hardware, policy, and protocol counters. For example, operators might deploy ThousandEyes probes on their customers' behalf, or even engage in federated data sharing as a means of gaining greater insight and in turn offering custom-tailored transport capabilities. Going further, customers taking advantage of demand-driven network services will have consumption patterns that can be fed to recommendation engines to further tailor their network experience.
Our vision is to evolve networks into agile platforms for operator innovation; or even better, agile platforms where customers can develop and implement their own transport innovations. Let's simplify underlying network infrastructures and interfaces and reduce complexity and heterogeneity. Let's collect normalized network data (GNMI and Openconfig), and house it in a proper big data system. Once we've taken those key steps, we can get going on that explosion of service innovation. And once we've ventured down that road, the network will be ready to take on the ML/AI frontier.
This is one blog in our "Perspectives on the Future of Service Provider Networking" series. Catch the rest coming from our group to learn more and get access to more content. In June we'll be hosting an interactive panel @CiscoLive: IBOSPG-2001 "Future Vision of SP Networking", where we'll share our point of view on the topics covered in this series. Please come join us and interact with our panel as this is an ongoing discussion.
 Hot Tags :
Networking
Service Provider
Artificial Intelligence (AI)
Machine Learning (ML)
#PerspectivesFutureSPNetworking
Hot Tags :
Networking
Service Provider
Artificial Intelligence (AI)
Machine Learning (ML)
#PerspectivesFutureSPNetworking
Register Email now for Weekly Promotion Stock
100% free, Unsubscribe any time!
Add 1: Room 605 6/F FA YUEN Commercial Building, 75-77 FA YUEN Street, Mongkok KL, HongKong Add 2: Room 405, Building E, MeiDu Building, Gong Shu District, Hangzhou City, Zhejiang Province, China
Whatsapp/Tel: +8618057156223 Tel: 0086 571 86729517 Tel in HK: 00852 66181601
Email: [email protected]
 English
English Pусский
Pусский Français
Français Español
Español Português
Português

