Register now for better personalized quote!
























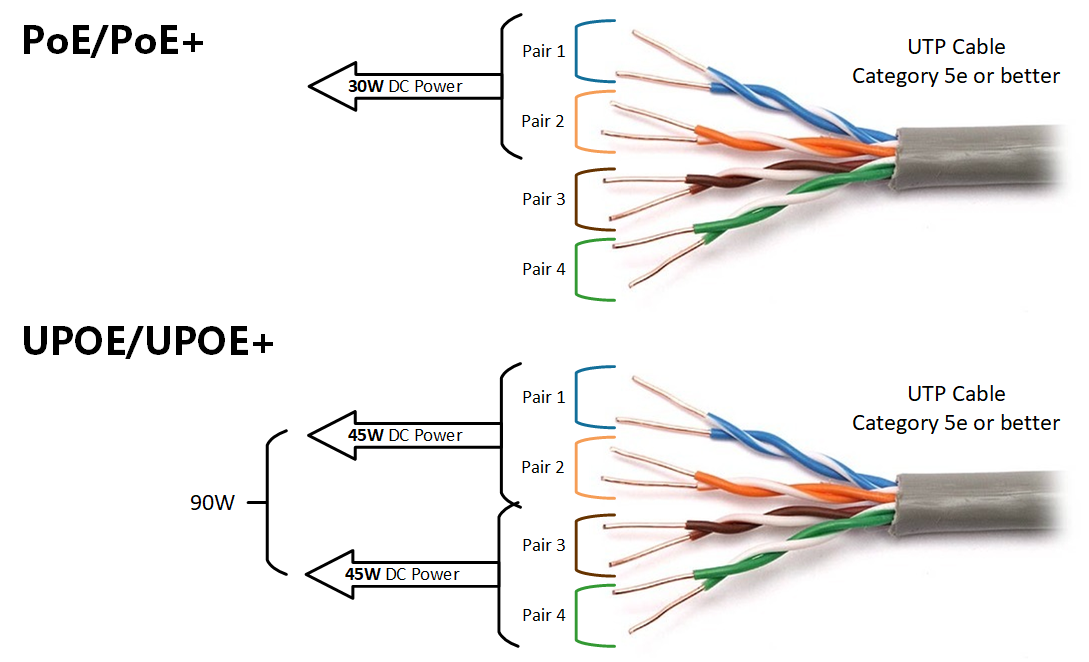



 Vithun Khamsong/Getty Images
Vithun Khamsong/Getty Images Organizations that want to harness generative artificial intelligence (AI) more effectively should use their own data to train AI systems, using foundation models as a starting point.
Doing so can provide more relevant context and allay concerns about the potential risks, such as inaccuracy and intellectual property infringements.
Also: How to use ChatGPT: Everything you need to know
Accuracy, in particular, is a top priority for a company such as Jiva. The agritech vendor uses AI to power its mobile app, Crop Doctor, which identifies crop diseases via image processing and computer vision, and recommends treatments. It also taps AI to determine the credit worthiness of farmers who ask for cash advancements prior to a harvest and returns the loans when their harvest pays out.
It uses various AI and machine-learning tools, including Pinecorn, OpenAI, and scikit-learn, as well as Google's TensorFlow and Vertex AI. Jiva has operations in Singapore, Indonesia, and India.
It trains its AI models on thousands of annotated images for each disease, according to Jiva's CTO Tejas Dinkar. The agritech company has collected hundreds of thousands of images from the ground through its field teams and farmers who are part of Jiva's network and use its app AgriCentral, which is available in India.
Also: How to use Bing Image Creator (and why it's better than DALL-E 2)
Its field experts are involved in the initial collection and annotation of images, before these are passed on to agronomy experts who further annotate the images. These then are added to the training model used to identify plant disease.
For new crops or crops that its team of experts are less familiar with, Jiva brings in other platforms, such as Plantix, which have extensive datasets to power image recognition and diagnosis information.
Delivering accurate information is vital because the data can improve farmers' harvests and livelihoods, Dinkar said in an interview with . To further ensure data veracity, generative AI and large language models (LLMs) use only datasets Jiva itself had sourced and vetted.
The chatbot is further asked, through prompt engineering, to ignore any pretrained data about farming that might be in the LLMs, he said.
Also: This new AI system can read minds accurately about half the time
If there's no data to draw from, the chatbot returns a response to say it is unable to identify the crop disease. "You want to ensure there's enough data. We don't want to provide a vague answer," he said.
Jiva also uses its image library to build on top of platforms, such as Plantix. These models provide a good baseline but, as they are developed by global companies, they may not necessarily be adequately trained on data specific to a region or market, Dinkar said.
This issue meant Jiva had to create training models for crops that were more common in Indonesia and India, such as corn, he said. These have been performing better than Plantix or other off-the-shelf products, he added, noting the importance of localization in AI models.
Using foundation data models out of the box is one way to get started quickly with generative AI. However, a common challenge with that approach is the data may not be relevant to the industry within which the business operates, according to Olivier Klein, Amazon Web Services' (AWS) Asia-Pacific chief technologist.
To be successful in their generative AI deployments, organizations should finetune the AI model with their own data, Klein said. Companies that take the effort to do this properly will move faster forward with their implementation.
Also: These experts are racing to protect AI from hackers
Using generative AI on its own will prove more compelling if it is embedded within an organization's data strategy and platform, he added.
Depending on the use case, a common challenge companies face is whether they have enough data of their own to train the AI model, he said. He noted, however, that data quantity did not necessarily equate data quality.
Data annotation is also important, as is applying context to AI training models so the system churns out responses that are more specific to the industry the business is in, he said.
With data annotation, individual components of the training data are labeled to enable AI machines to understand what the data contains and what components are important.
Klein pointed to a common misconception that all AI systems are the same, which is not the case. He reiterated the need for organizations to ensure they tweak AI models based on the use case as well as their vertical.
LLMs have driven many conversations among enterprise customers about the use of generative AI in call centers, in particular, he said. There is interest in how the technology can enhance the experience for call agents, who can access better responses on-the-fly and incorporate these to improve customer service.
Call center operators can train the AI model using their own knowledge base, which can comprise chatbot and customer interactions, he noted.
Adding domain-specific content to an existing LLM already trained on general knowledge and language-based interaction typically requires significantly less data, according to a report by Business Harvard Review. This finetuning approach involves adjusting some parameters of a base model and uses just hundreds or thousands of documents, rather than millions or billions. Less compute time is also needed, compared to building a new foundational model from ground zero.
Also: Generative AI can make some workers a lot more productive, according to this study
There are some limitations, though. The report noted that this approach still can be expensive and requires data science expertise. Furthermore, not all providers of LLMs, such as OpenAi's ChatGPT-4, permit users to finetune on top of theirs.
Tapping their own data also addresses a common concern customers have amid the heightened interest in generative AI, where businesses want to retain control of the data used to train AI models and have the data remain within their environments, Klein said.
This approach ensures there is no "blackbox" and the organization knows exactly what data is used to feed the AI model, he noted. It also assures transparency and helps establish responsible AI adoption.
There also are ongoing efforts in identifying policies needed to avoid the blackbox effect, he said, adding that AWS works with regulators and policy makers to ensure its own AI products remain compliant. The company also help customers do likewise with their own implementations.
Also: People are turning to ChatGPT to troubleshoot their tech problems now
Amazon Bedrock, for instance, can detect bias and filter content that breaches AI ethical guidelines, he said. Bedrock is a suite of foundation models that encompass proprietary as well as industry models, such as Amazon Titan, AI21 Labs' Jurassic-2, Anthropic's Claude, and Stability AI.
Klein anticipates that more foundation data models will emerge in future, including vertical-specific base models, to provide organizations with further options on which to train.
Where there is a lack of robust AI models, humans can step back in.
For rare or highly specific crop issues, Dinkar noted that Jiva's team of agronomy experts can work with local researchers and field teams to resolve them.
The company's credit assessment team also overlays data generated by the AI systems with other information, he said. For example, the team may make an on-site visit and realize a crop is just recently ready for harvest, which the AI-powered system may not have taken into consideration when it generated the credit assessment.
"The objective is not to remove humans entirely, but to move them to areas they can amplify and [apply] adaptive thoughts, which machines aren't yet up to," Dinkar said.
Asked about challenges Jiva encountered with its generative AI adoption, he pointed to the lack of a standard prompt methodology across difference software versions and providers.
"True omni-lingualism" also is missing in LLMs, he said, while hallucination remains a key issue.
"Various large language models all have their own quirks [and] the same prompt techniques do not work across these," he explained. For instance, through refined prompt engineering, Jiva has been able to instruct its agronomy bot to clarify if it is unable to infer, from context, the crop that the farmer is referencing.
Also: How I tricked ChatGPT into telling me lies
However, while this particular prompt performed well on GPT-3.5, it did not do as well on GPT-4, he said. It also does not work on a different LLM.
"The inability to reuse prompts across versions and platforms necessitates the creation of bespoke sets of prompt techniques for each one," Dinkar said. "As tooling improves and best practices emerge for prompting various large language models, we hope cross-platform prompts will become a reality."
Improvements are also needed in cross-language support, he said, pointing to strange responses that its chatbot sometimes generates that are out of context.
 Hot Tags :
Artificial Intelligence
Innovation
Hot Tags :
Artificial Intelligence
Innovation
Register Email now for Weekly Promotion Stock
100% free, Unsubscribe any time!
Add 1: Room 605 6/F FA YUEN Commercial Building, 75-77 FA YUEN Street, Mongkok KL, HongKong Add 2: Room 405, Building E, MeiDu Building, Gong Shu District, Hangzhou City, Zhejiang Province, China
Whatsapp/Tel: +8618057156223 Tel: 0086 571 86729517 Tel in HK: 00852 66181601
Email: [email protected]
 English
English Pусский
Pусский Français
Français Español
Español Português
Português

