Register now for better personalized quote!
























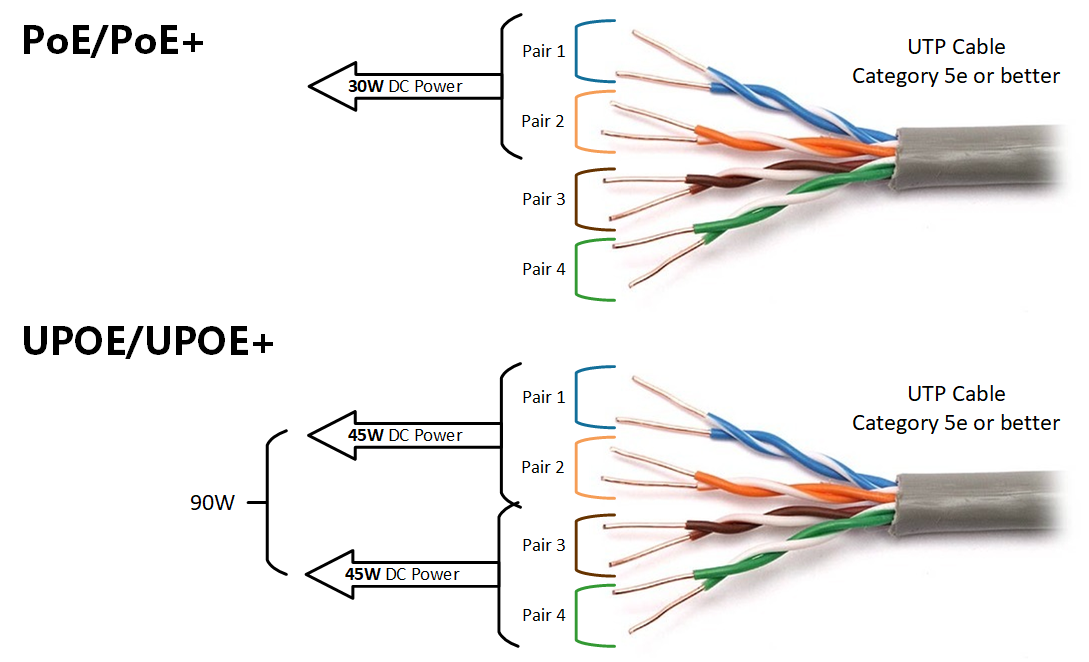




A Google data center with racks of its TPU version 4 accelerator chips for crunching machine learning. Google used a cluster of 2,048 TPUs to train its largest-ever version of its BERT natural language program, consisting of 481 billion parameters, in 19 hours, as a submission to the MLPerf benchmark competition.
GoogleThe deep learning world of artificial intelligence is obsessed with size.
Deep learning programs, such as OpenAI's GPT-3, continue using more and more GPU chips from Nvidia and AMD -- or novel kinds of accelerator chips -- to build ever-larger software programs. The accuracy of the programs increases with size, researchers contend.
That obsession with size was on full display Wednesday in the latest industry benchmark results reported by MLCommons, which sets the standard for measuring how quickly computer chips can crunch deep learning code.
Google decided not to submit to any standard benchmark tests of deep learning, which consist of programs that are well-established in the field but relatively outdated. Instead, Google's engineers showed off a version of Google's BERT natural language program, which no other vendor used.
MLPerf, the benchmark suite used to measure performance in the competition, reports results for two segments: the standard "Closed" division, where most vendors compete on well-established networks such as ResNet-50; and the "Open" division, which lets vendors try out non-standard approaches.
It was in the Open division that Google showed a computer using 2,048 of Google's TPU chips, version 4. That machine was able to develop the BERT program in about 19 hours.
Also:AI in sixty seconds
The BERT program, a neural network with 481 billion parameters, had not previously been disclosed. It is over three orders of magnitude larger than the standard version of BERT in circulation, known as "BERT Large," which has just 340 million parameters. Having many more parameters typically requires much more computing power.
Google said the novel submission reflects the increasing importance of scale in AI.
Google submitted the novel version of its BERT language program in the "Open" division of MLPerf. Graphcore and Samsung were the other two vendors participating in this division.
MLCommons"Our thinking this time around is, we've always been keen to make sure that our submissions to MLPerf are well-aligned to our internal needs, and the needs of the ML industry," said Aarush Selvan, who oversees machine learning infrastructure for Google, in a media briefing.
"And so, training large models -- models on the order of tens or hundreds of billions of parameters, and even a trillion parameters and above, is increasingly important both within Google -- it's a huge set of focus for our research and our production -- but also for our cloud customers."
The MLPerf test suite is the creation of MLCommons, an industry consortium that issues multiple annual benchmark evaluations of computers for the two parts of machine learning: so-called training, where a neural network is built by having its settings refined in multiple experiments; and so-called inference, where the finished neural network makes predictions as it receives new data.
Wednesday's report is the latest benchmark test for the training phase. It follows the prior report in June.
The full MLPerf results were discussed in a press release on the MLCommons site. The complete data on submissions can be seen in tables posted on the site.
Also:Graphcore brings new competition to Nvidia in latest MLPerf AI benchmarks
Google's Selvan said MLCommons should consider including more large models. The older, smaller networks like ResNet-50 "only give us a proxy" for large-scale training performance, he said.
"Throwing 4,000 chips to train BERT in just a few seconds is really cool," observed Selvan, referring to the smaller version of BERT most vendors focus on in the Closed division.
"And showcases some aspects of scalability, but it's really just a proxy, because in real life, you never use that many chips to train that small a model."
"Throwing 4,000 chips to train BERT in just a few seconds is really cool," observed Selvan, referring to the smaller version of BERT most vendors focus on in the Closed division. "And showcases some aspects of scalability, but it's really just a proxy, because in real life, you never use that many chips to train that small a model."
MLCommonsThe missing component, said Selvan, is the so-called efficiency of systems as they get bigger. Google was able to run its giant BERT model with 63% efficiency, he toldZDNet, as measured by the number of floating point operations per second performed relative to a theoretical capacity. That, he said, was better than the next-highest industry result, 52%, achieved by Nvidia in the development of its Megatron-Turing language model developed with Microsoft.
"Going forward, we think it would be really awesome to have some kind of large-model benchmark within the MLPerf competition," Selvan said.
David Kanter, executive director of MLCommons, said the decision to have large models should be left to the members of the Commons to decide collectively. He pointed out, however, that the use of small neural networks as tests makes the competition accessible to more parties.
"The point of a benchmark is to be fair and representative, but also to not bankrupt anyone running it," said Kanter.
"In theory we could make training GPT-3 an MLPerf benchmark," added Kanter, referring to the 175-billion parameter language model introduced by OpenAI last year as a state-of-the-art natural language model.
"The point of a benchmark is to be fair and representative, but also to not bankrupt anyone running it," said MLCommons chair Kanter. "In theory, we could make training GPT-3 an MLPerf benchmark ... The challenge is, training GPT-3 is quite computationally expensive. It's tens of millions of dollars."
MLCommons"The challenge is, training GPT-3 is quite computationally expensive. It's tens of millions of dollars."
By contrast, the standard tests of MLPerf, whose code is made available to everyone, are a resource any AI researcher can grab to replicate the tests -- without having exotic approaches to compute, said Kanter.
"In that way, it produces these very valuable engineering artifacts for the entire community and helps drive the industry forward."
Google has no plans to publish on the novel BERT model, Selvan toldZDNetin an email, describing it as "something we did just for MLPerf." The program is similar to designs outlined in research by Google earlier this year on highly parallelized neural networks, said Selvan.
Despite the novelty of the 481-billion-parameter BERT program it is representative of real-world tasks because it builds on real-world code.
"We do believe that these benchmarks we submitted, because they leverage a stacked Transformer architecture, are fairly realistic in terms of their compute characteristics with existing large language models that have been published," Selvan toldZDNet.
Like the smaller submissions in MLPerf, the giant BERT model was trained to produce results with a certain accuracy, explains Selvan. In this case, 75% accuracy in predictions, above the 72.2% required by MLPerf.
Nvidia chips once again took the lion's share of top scores to train neural nets, with some help this time from Microsoft Azure.
NvidiaThe Google program also relied on fewer samples of text data to reach the same accuracy as the Closed division results of other vendors. The Closed division requires a program to train with almost half a billion sequences of tokens, mostly of a length of 128 tokens per sequence. The Google program was trained using only about 20 million tokens, but at a length of 512 tokens per sequence. The work is discussed in more detail in a blog post by Google.
The 2,048-TPU system Google used to do the work is currently available as a Google Cloud service.
The rest of the MLPerf results, mostly in the Closed division, showcase Nvidia and other vendors continuing to make progress in reducing the time it takes to train the standard versions of ResNet, BERT, and other tasks.
Nvidia, as always, took the lion's share of top results. For example, computers using its latest generation of GPU, the A100, took the top four spots for the fastest time to train ResNet-50, the fastest being just 21 seconds. That was with 4,320 A100s operating in parallel, with the help of 1,080 AMD's EPYC x86 processors. The result was an improvement over the 24 seconds Nvidia notched in the June report.
However, where systems used fewer Nvidia chips and fewer host processors, competitors were able to score higher than Nvidia. Intel's Habana Labs took fifth place in ResNet-50 with 256 of of Habana's Gaudi accelerator chips overseen by 128 Intel Xeons.
Graphcore made the case it can deliver better results at much less cost than Nvidia's systems, a bigger part of the savings being fewer host procesors from Intel or AMD needed for an equivalent number of AI accelerators.
GraphcoreAnd Graphcore, the Bristol, UK-based startup that showed the best score in the June report for a two-processor system on BERT training, took the sixth place on ResNet-50 with a new version of its IPU-POD computer that uses 256 of its IPU accelerator chips and 32 AMD EPYC host processors.
The Habana and the Graphcore ResNet-50 results were 3.4 minutes and 3.8 minutes, respectively. That compares to 4.5 minutes required by Nvidia's 7th-place entry, a 64-way A100 system with 16 EPYC processors.
As in the June report, the first time Graphcore participated, the company stressed the importance of striking a balance between performance and cost of the overall systems. The company cited the time-to-time-train ResNet-50 of 28 minutes on its 16-way system, a minute faster than a comparable Nvidia DGXA100 system costing substantially more, it said.
"Our POD-16 outperforms a DGXA100... and it's half the list price of the DGXA100," said Dave Lacey, Graphcore's chief software architect, in a media briefing.
Much of the cost advantage comes from having a smaller ratio of Intel or AMD x86 host processors relative to IPU chips, said Graphcore.
Graphcore came in sixth place behind Nvidia chips for top scores training the standard BERT model, at almost 7 minutes versus 3 minutes for the fifth-place Nvidia system. However, the Graphcore system used just 4 AMD EPYC processors versus 16 in the Nvidia-based system.
"The host processor price is a significant part of the cost of a system," said Lacey. "Like any expensive resource, you only use what you need."
Graphcore makes the case its low ratio of host processor -- Intel or AMD x86 -- to accelerator chip is a more-efficient model of AI processing that leads to substantial cost savings.
GraphcoreAsked about Google's point regarding large neural net tasks, Lacey said the main MLPerf results serve well as a proxy for real-world tasks.
Over and above individual vendor achievements, the MLPerf benchmark demonstrates the total chip industry's achievement in speeding up performance on neural networks, said MLCommons Chair Kanter.
"If you look at the trajectory of the best results in MLPerf training over time, you can see that it is dramatically faster than Moore's Law," said Kanter, referring to the semiconductor rule of thumb for many decades that transistor density doubles roughly every 18 months, leading to a doubling in performance.
"Through optimizations to architecture, to system size, to software, to model partitioning," said Kanter, vendors are managing to speed up neural net performance as much as 11 times faster than Moore's Law's historical trajectory.
The benchmark suite continues to gain support from vendors, with more participants and more submissions. Results reported for all the benchmarks in aggregate totaled 175, up from 144 in the June report.
New vendors joined the competition this time around. Samsung Electronics, for example, submitted results from its supercomputer using 256 AMD chips and 1,024 Nvidia A100s. That system, with the help of some non-standard software tweaks, had the second-fastest score of all systems to train the normal version of BERT, just 25 seconds.
Also a newcomer this time wasMicrosoft's Azure cloud service, which reported results for 19 submissions using AMD processors and Nvidia A100s in various configurations. Azure won two of the top five spots in seven out of the eight benchmark tests.
And one Azure system took the top score to train an image segmentation model on medical data (the KiTS19 challenge), using 192 AMD EPYC processors and 768 A100s.
"We want to democratize supercomputing," Nidhi Chappell, head of high-performance computing and AI at Azure, toldZDNet.
She said that making commercially-available systems, such as the 768-way AI100 system, in the cloud has "brought together the best of HPC and AI, instead of taking a vanilla cloud that serves every workload."
"AI training is an HPC problem, and our expertise in HPC has helped us to build AI at scale," she said. "We want to build infrastructure that is optimized for large scale." This includes systems that have as many as 80,000 cores.
Microsoft shows its Azure cloud service is "democratizing high-performance computing" with its first MLPerf training submission, conducted in cooperation with Nvidia.
Microsoft AzureAn important reason to participate in MLPerf, said Chappell, was to show that such large-scale work can perform as well in a cloud environment as it does on-premise.
"What we have proven is we have been able to mask the overhead of cloud virtualization; that overhead is pretty much remote in cloud," so that it doesn't drag down performance, she said.
Asked about large models versus the standard MLPerf tasks, Chappell said "it's only a matter of time" before Azure submits some non-standard, large-scale works similar to what Google has done in the Open division.
"It will happen."
At the same time, the standard MLPerf tests in the Closed division are useful, she said, because they "show how fast AI is evolving; it is a constant process of optimization."
Also: Ethics of AI: Benefits and risks of artificial intelligence
Chappell's collaborator at Nvidia, Shar Narasimhan, Nvidia's senior group product manager for its data center products, said in the same briefing that MLPerf's standard tests have the virtue of being like a uniform track where many athletes compete on a level field.
"It serves as an opportunity for everyone to run the exact same race, and compare the results head to head," said Narasimhan. "When we look at Olympic results, we have had the exact same track for more than a century, and that allows you to compare the race that was run 100 years ago with [Jamaican sprinter] Usain Bolt's results."
Of course, with the world's largest published NLP model, Megatron-Turing, it would seem Nvidia and Azure could offer a novel submission of large models as Google did.
"We can't compare those models with anyone else," explained Narasimhan, so it's hard to make such work useful in the context of MLPerf. Nvidia has not committed to any future large-model submissions.
In terms of what is important to the industry, said Narasimhan, is that many companies want to use AI for focused purposes, "not a giant language model that needs 4,000 chips to run." The smaller benchmarks can be used to anticipate workloads and performance, he said.
Google's Selvan said Google intends to continue to submit to the Closed division benchmarks of MLPerf in future.
"We'll see everybody back in the Closed division next year -- hopefully, can't promise, but we plan to be there," he said.
 Hot Tags :
Artificial Intelligence
Innovation
Hot Tags :
Artificial Intelligence
Innovation
Register Email now for Weekly Promotion Stock
100% free, Unsubscribe any time!
Add 1: Room 605 6/F FA YUEN Commercial Building, 75-77 FA YUEN Street, Mongkok KL, HongKong Add 2: Room 405, Building E, MeiDu Building, Gong Shu District, Hangzhou City, Zhejiang Province, China
Whatsapp/Tel: +8618057156223 Tel: 0086 571 86729517 Tel in HK: 00852 66181601
Email: [email protected]
 English
English Pусский
Pусский Français
Français Español
Español Português
Português

