Register now for better personalized quote!































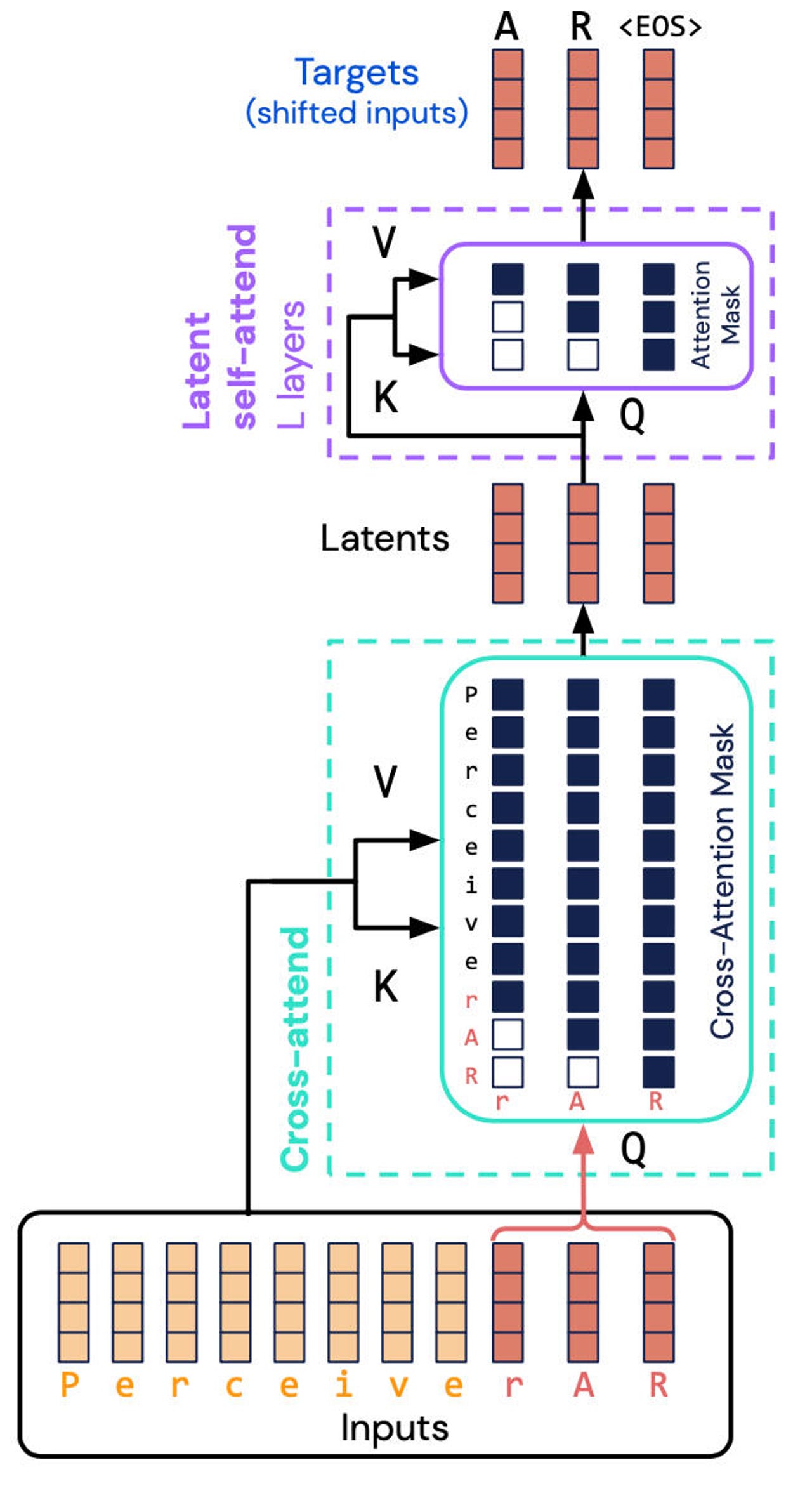
DeepMind and Google Brain's Perceiver AR architecture reduces the task of computing the combinatorial nature of inputs and outputs into a latent space, but with a twist that the latent space has "causal masking" to add the auto-regressive orderof a typical Transformer.
DeepMind/Google BrainOne of the alarming aspects of the incredibly popular deep learning segment of artificial intelligence is the ever-larger size of the programs. Experts in the field say computing tasks are destined to get bigger and biggest because scale matters.
Such bigger and bigger programs are resource hogs, and that is an important issue in the ethics of deep learning for society, a dilemma that has caught the attention of mainstream science journals such as Nature.
That's why it's interesting any time that the term efficiency is brought up, as in,Can we make this AI program more efficient?
Scientists at DeepMind, and at Google's Brain division, recently adapted a neural network they introduced last year, Perceiver, to make it more efficient in terms of its computer power requirement.
The new program, Perceiver AR, is named for the "autoregressive" aspect of an increasing number of deep learning programs. Autoregression is a technique for having a machine use its outputs as new inputs to the program, a recursive operation that forms an attention map of how multiple elements relate to one another.
Also:Google's Supermodel: DeepMind Perceiver is a step on the road to an AI machine that could process anything and everything
The Transformer, the wildly popular neural network Google introduced in 2017, has this autoregressive aspect. And many models since do, including GPT-3 and the first version of the Perceiver.
Perceiver AR follows a second version of Perceiver, called Perceiver IO, introduced in March, and the original Perceiver a year ago this month.
The innovation of the original perceiver was to take the Transformer and tweak it to let it consume all kinds ofinput, including text sound and images, in a flexible form, rather than being limited to a specific kind of input, for which separate kinds of neural networks are usually developed.
Perceiver is one of an increasing number of programs that use auto-regressive attention mechanisms to mix different modalities of input and different task domains. Other examples include Google's Pathways, DeepMind's Gato, and Meta's data2vec.
Also:DeepMind's 'Gato' is mediocre, so why did they build it?
Then, in March, the same team of Andrew Jaegle and colleagues that built Perceiver, introduced the "IO" version, which enhanced theoutputof Perceiver to accommodate more than just classification, achieving a host of outputs with all kind of structure, ranging from text language output to optical flow fields to audiovisual sequences to symbolic unordered sets. It can even produced movement in the game StarCraft II.
Now, in the paper, General-purpose, long-context autoregressive modeling with Perceiver AR, Jaegle and team confront the question of how the models should scale as they become more and more ambitious in those multimodal input and output tasks.
The problem is, the auto-regressive quality of the Transformer, and any other program that builds an attention map from input to output, is that it requires tremendous scale in terms of the a distribution over hundreds of thousands of elements.
That is the Achilles Heel of attention, the need, precisely, to attend to anything and everything in order assemble the probability distribution that makes for the attention map.
Also:Meta's 'data2vec' is a step toward One Neural Network to Rule Them All
As Jaegle and team put it, it becomes a scaling nightmare in computing terms as the number of things that have to be compared to one another in the input increases:
There is a tension between this kind of long-form, contextual structure and the computational properties of Transformers. Transformers repeatedly apply a self-attention operation to their inputs: this leads to computational requirements that simultaneously grow quadratically with input length and linearly with model depth. As the input data grows longer, more input tokens are needed to observe it, and as the pat- terns in the input data grow more subtle and complicated, more depth is needed to model the patterns that result. Computational constraints force users of Transformers to either truncate the inputs to the model (preventing it from observ- ing many kinds of long-range patterns) or restrict the depth of the model (denuding it of the expressive power needed to model complex patterns).
The original Perceiver in fact brought improved efficiency over Transformers by performing attention on a latent representation of input, instead of directly. That had the effect of "[decoupling] the computational requirements of processing a large input array from those required to make a network very deep."
Perceiver AR's comparison to a standard Transformer deep network and the enhanced Transformer XL.
DeepMind/Google BrainThe latent part, where representations of input are compressed, becomes a kind of more-efficient engine for attention, so that, "For deep networks, the self-attention stack is where the bulk of compute occurs" rather than operating on myriad inputs.
But the challenge remained that a Perceiver cannot generate outputs the way the Transformer does because that latent representation has no sense of order, and order is essential in auto-regression. Each output is supposed to be a product of what camebeforeit, not after.
Also:Google unveils 'Pathways', a next-gen AI that can be trained to multitask
"However, because each model latent attends to all inputs regardless of position, Perceivers cannot be used directly for autoregressive generation, which requires that each model output depend only on inputs that precede it in sequence," they write.
With Perceiver AR, the team goes one further and insertsorder into the Perceiver to make it capable of that auto-regressive function.
The key is what's called "causal masking" of both the input, where a "cross-attention takes place, and the latent representation, to force the program to attend only to things preceding a given symbol. That approach restores the directional quality of the Transformer, but with far less compute.
The result is an ability to do what the Transformer does across many more inputs but with significantly improved performance.
"Perceiver AR can learn to perfectly recognize long-context patterns over distances of at least 100k tokens on a synthetic copy task," they write, versus a hard limit of 2,048 tokens for the Transformer, where more tokens equals longer context, which should equal more sophistication in the program's output.
Also:AI in sixty seconds
And Perceiver AR does so with "improved efficiency compared to the widely used decoder-only Transformer and Transformer-XL architectures and the ability to vary the compute used at test time to match a target budget."
Specifically, the wall clock time to compute Perceiver AR, they write, is dramatically reduced for the same amount of attention, and an ability to get much greater context - more input symbols - at the same computing budget:
The Transformer is limited to a context length of 2,048 tokens, even with only 6 layers-larger models and larger context length require too much memory. Using the same 6-layer configuration, we can scale the Transformer-XL memory to a total context length of 8,192. Perceiver AR scales to 65k context length, and can be scaled to over 100k context with further optimization.
All that means flexibility of compute: "This gives us more control over how much compute is used for a given model at test time and allows us to smoothly trade off speed against performance."
The approach, Jaegle and colleagues write, can be used on any input type, not just word symbols, for example, pixels of an image:
The same procedure can be applied to any input that can be ordered, as long as masking is applied. For example, an image's RGB channels can be ordered in raster scan order, by decoding the R, G, and B color channels for each pixel in the sequence or even under different permutations.
Also:Ethics of AI: Benefits and risks of artificial intelligence
The authors see big potential for Perceiver to go places, writing that "Perceiver AR is a good candidate for a general-purpose, long-context autoregressive model."
There's an extra ripple, though, in the computer efficiency factor. Some recent efforts, the authors note, have tried to slim down the compute budget for auto-regressive attention by using "sparsity," the process of limiting which input elements are given significance.
At the same wall clock time, the Perceiver AR can run more symbols from input through the same number of layers, or run the same number of input symbols while requiring less compute time -- a flexibilty the authors believe can be a general approach to greater efficiency in large networks.
DeepMind/Google BrainThat has some drawbacks, principally, being too rigid. "The downside of methods that use sparsity is that this sparsity must be hand-tuned or created with heuristics that are often domain specific and can be hard to tune," they write. That includes efforts such as OpenAI and Nvidia's 2019 "Sparse Transformer."
"In contrast, our work does not force a hand-crafted sparsity pattern on attention layers, but rather allows the network to learn which long-context inputs to attend to and propagate through the network," they write.
"The initial cross-attend operation, which reduces the number of positions in the sequence, can be viewed as a form of learned sparsity," they add.
It's possible learned sparsity in this way could itself be a powerful tool in the toolkit of deep learning models in years to come.
 Hot Tags :
Artificial Intelligence
Innovation
Hot Tags :
Artificial Intelligence
Innovation
Register Email now for Weekly Promotion Stock
100% free, Unsubscribe any time!
Add 1: Room 605 6/F FA YUEN Commercial Building, 75-77 FA YUEN Street, Mongkok KL, HongKong Add 2: Room 405, Building E, MeiDu Building, Gong Shu District, Hangzhou City, Zhejiang Province, China
Whatsapp/Tel: +8618057156223 Tel: 0086 571 86729517 Tel in HK: 00852 66181601
Email: info@hi-network.com
 English
English Pусский
Pусский Français
Français Español
Español Português
Português

