Register now for better personalized quote!































A simple task, to reduce all the words in an article to a compact sequence of words that explains the article's central point, is among the benchmark tasks in deep learning. This is where Amazon's Alexa AI scientists say they can best the efforts of vastly larger computer programs from DeepMind, Google, Meta, OpenAI, and others. The work has implications for energy use and carbon footprint-efficiency.
Amazon Alexa AI 2022Two threads of research strongly dominate machine learning these days: making programs more general in their approach (to handle any potential task) and making them bigger.
The biggest neural nets, as measured by their parameters or "weights," are clocking in at over half a trillion weights. Models such as Google's Pathways Language Model, or PaLM, and Nvidia and Microsoft's Megatron-Turing NLG 530B are among the biggest, with 540 billion and 530 billion parameters, respectively. The more parameters a program has, in general, the greater the amount of computing power it consumes to train, and also to run for making predictions, what's calledinference.
The cognoscenti of AI insist the path is definitely up and to the right for parameter count, toward a trillion parameters and way beyond in the not-so-distant future. The figure of 100 trillion is a kind of magical target because it is believed to be the number of synapses in a human brain, so it serves as a benchmark of sorts.
Also:Nvidia clarifies Megatron-Turing scale claim
At the same time, there is a fervor to make deep neural networks that can be as general as possible. For much of the machine learning history of the last 40 years, programs were specialized for tasks such as image recognition or speech recognition. That has changed in recent years, with more and more programs offering to be generalists, such as DeepMind's Perceiver AR, and another DeepMind program, Gato, referred to as "a generalist agent" capable of solving myriad tasks.
The generalizing tendency has been reinforced by the observations of machine learning pioneers such as Richard Sutton, who has remarked that "historically, generic models that are better at leveraging computation have also tended to overtake more specialized domain-specific approaches eventually."
Also:DeepMind's 'Gato' is mediocre, so why did they build it?
And yet, there are deep learning results that sometimes run the other way: against giant and general to economical and somewhat focused, if not specialized.
In contrast to those mega-efforts, researchers at Amazon last week unveiled a neural net program with only 20 billion parameters that outperforms some of the biggest, most general models on some important benchmark tasks of deep learning, such as how to summarize an article.
In the paper, "AlexaTM 20B: Few-Shot Learning Using a Large-Scale Multilingual Seq2Seq Model," posted last week on arXiv, author Saleh Soltan and colleagues at Amazon Alexa AI show 20 billion parameters is sufficient to beat larger models like PaLM on certain tasks, such as summarizing an article in a few sentences.
In addition to the paper, Soltan has written a blog post on the topic.
Amazon's work is part of a broad trend in recent literature to find alternatives to increasing size. A paper released last week from Meta (owners of Facebook and Instagram) titled "Few-shot Learning with Retrieval Augmented Language Models" is a good example. It describes a language model called Atlas that has only 11 billion parameters and is trained using a mere 64 example data points.
As with AlexaTM 20B, the Atlas program beats PaLM by a significant margin, the authors write, even with just the 64 examples. The key to Atlas is to combine the pre-trained language model with an ability to retrieve information from online sources, such as Wikipedia, as if phoning a friend for the answer.
Also:DeepMind's Perceiver AR: A step toward more AI efficiency
In the case of AlexaTM 20B, the Amazon authors use three tweaks to achieve their scores.
Amazon 2022 AlexTM 20B Diagram
AmazonThe first interesting tweak is to go back to basics and restore something taken out of recent giant language models. The basis of AlexaTM 20B is the same as PaLM and GPT-3 and others, a Transformer encoder-decoder -- the approach pioneered in 2017 by Google scientists Ashish Vaswani and colleagues.
The Transformer uses units called "self-attention" to come up with a probability score for how every word may be found in the context of other words. That score is then used to fill in the blanks when predicting words to form meaningful text blocks.
In the case of AlexaTM 20B, Soltan and colleagues make a critical departure from PaLM and GPT-3 and other gigantic descendants of the original Transformer. Those more-recent models dispensed with one half of the Transformer, what's called the encoder (the thing that maps input data into hidden states to then be decoded into an answer). Instead, PaLM and GPT-3 merge the input with the decoder, to form a stripped-down program that is a "decoder-only" model.
The Alexa team puts the encoder back into the program. Their claim is that having both elements helps to improve accuracy in what's called "de-noising," which means reconstructing an original sentence where some of the words have dropped out.
In the decoder-only model, the conditional probability of predicted text runs only in one direction: every next answer is based only on what came before. In the full encoder-decoder version, by contrast, the model is making an assessment of probabilities in both directions: what came before a given word and what follows. That serves better in tasks where one is not only generating the next element in a sentence, but also doing things like word-for-word comparison, as in translation tasks from one language to another.
Amazon 2022 AlexTM 20B Decoder-Only Models
AmazonAlso:Meta's massive multilingual translation opus still stumbles on Greek, Armenian, Oromo
As they write, "AlexaTM 20B achieves a new state-of-the-art of 82.63% in the zero-shot setting in the denoising mode. The main reason denoising mode performs better for this task is that in the denoising mode, the input is being repeated in encoder and decoder allowing the model to use both encoder and decoder fully to find the best answer."
The second thing the authors add is to train the model with what's called "causal language modeling." CLM, for short, is the task that is used in GPT-3 and other decoder-only Transformers. It specifically represents every word as dependent only on the words that came before -- a sequential, one-way dependency that is trained to generate sentences based on an initial prompt.
The authors mix the de-noising task with the causal task in training AlexaTM 20B, with de-noising taking up 80% of the training activity and causal modeling the remaining fifth.
The virtue of adding causal modeling is that, similar to GPT-3, it aids in what is called "in-context learning." In-context learning is a broad rubric covering any models that are able to perform zero- or few-shot learning. That means that the program has no domain-specific knowledge; you just give it an example prompt, and the program makes a prediction that is in accord with the type of question being posed.
Because of that hybrid training regime, AlexTM 20B not only does well at reconstructing sentences -- the de-noising task, it also is "the first multilingual seq2seq [sequence to sequence] model capable of in-context learning," the authors write. It's a hybrid program, in other words.
The third interesting tweak by Soltan and colleagues is to increase enormously how many data points are input to the program during training. They input one trillion "tokens," individual pieces of data, during training; that's more than three times as many as GPT-3 receives. The training data sets in this case consist of Wikipedia entries and also what's called mC4, a data set for training Transformers introduced last year by Linting Xue and colleagues at Google. It's based on natural-language text in 101 languages from the Common Crawl Web-scraped data sources.
Also:Sentient? Google LaMDA feels like a typical chatbot
The use of a very large amount of input training data is one of the key elements of the Alexa work. Soltan and team decided to go that route, they write, based on an observation made by Jordan Hoffman and colleagues at OpenAI, as published in a paper this past March, "Training compute-optimal large language models."
In that paper, Hoffman and colleagues conclude that "current large language models are significantly under-trained, a consequence of the recent focus on scaling language models whilst keeping the amount of training data constant." By taking a wide range of language models of different sizes and testing them all with varying amounts of input tokens, the authors concluded that "for compute-optimal training, the model size and the number of training tokens should be scaled equally."
Hence, AlexaTM 20B is not just parsimonious -- it aims to prove that fewer parameters can be balanced with more training data to equal compelling performance.
Amazon now has an entire army of Echo devices. Some listen to you. Some also watch you. Which should you choose? We help you decide.
Read nowIncidentally, the authors also take pains to shape the majority of the input as naturalspokentext, dropping capitalization and punctuation, which has importance in an Alexa setting. "We include more spoken than written text to satisfy our internal use cases," they write.
Some of the Alexa AI team's technologies are used in Alexa products, although Amazon toldZDNetin an email that the group "also [does] forward-looking research." The AlexaTM 20B model, said Amazon, "is primarily a research project at this stage."
Added Amazon, "It's possible that this model will be deployed in production in the future, but only the modified version with guardrails will be used to develop Alexa features and products."
Also:Google's massive language translation work identifies where it goofs up
The authors train the AlexaTM 20B model "for 120 days on 128 [Nvidia] A100 GPUs for the total of 500k updates with the accumulated batch size of 2 million tokens (total of 1 trillion token updates)," they write.
That might sound like a lot, but it's less than PaLM, which was trained by Google on two of its fourth-generation TPU Pods, consisting of 3,072 TPU chips in each Pod, which are attached to 768 host computers.
As Google authors Aakanksha Chowdhery and team noted in April, that was "the largest TPU configuration described to date."
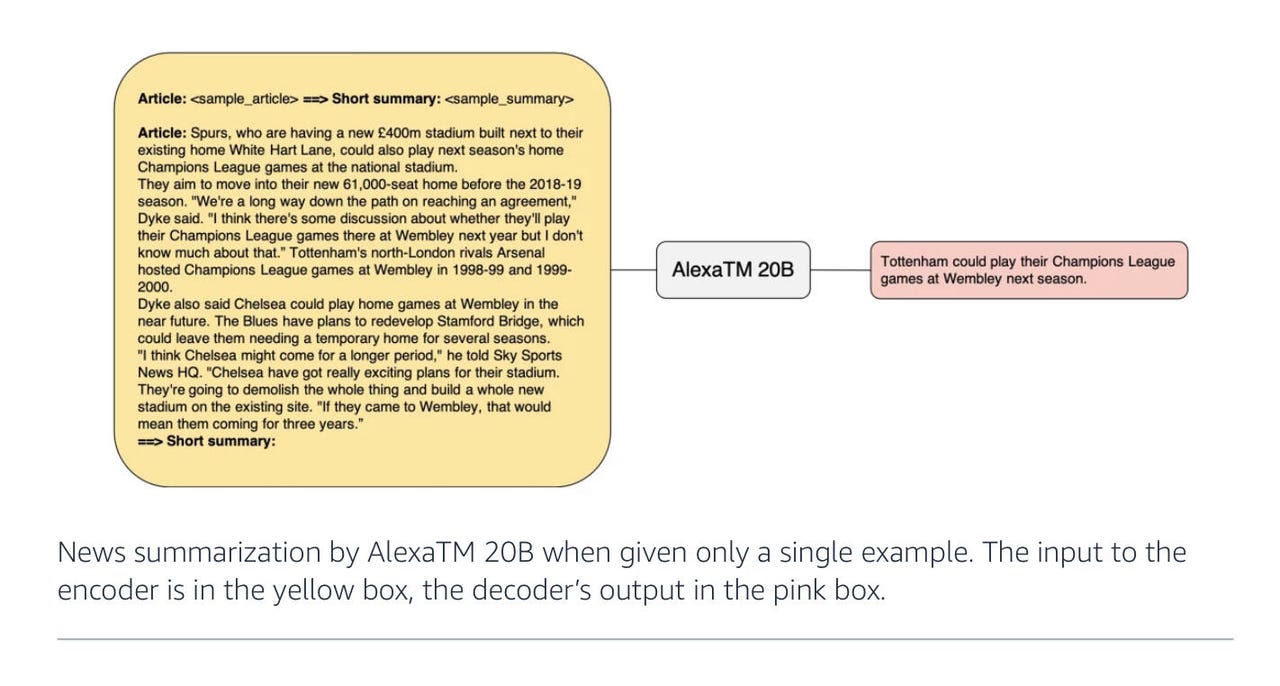
The results are spelled out in specific test results. Soltan and team place a special emphasis on their success in particular tasks as opposed toeverytask conceivable. For example, Soltan and team observe that "AlexaTM 20B performs better or in par to the largest dense decoder-only model to date (i.e., PaLM 540B) in summarization both in 1-shot and fine-tuning settings." This is specifically true in a task of summarizing paragraphs known as MLSum; in German, Spanish, and French, AlexaTM 20B beat PaLM handily.
The MLSum benchmark test, introduced in 2020 by France's National Centre for Scientific Research, comprises 1.5 million articles from newspapers. The task is for a language model to output a few sentences of text that express the idea laid out in the entire article. This requires a lot of reduction, obviously, of hundreds of words down to perhaps a few dozen.
On a fourth test, XSum, performed in English, the AlexaTM 20B model was a close second, and it beat out a version of PaLM that was bigger than AlexaTM 20B but smaller than the 540-billion-parameter version of PaLM.
While it excels at summarization, the AlexTM 20B falls down on some other tasks. For example, tested on "reasoning" data sets (such as MultiArith) and "chain of thought" reasoning tasks (which are very simple arithmetic problems written in natural language), the program falls far behind what is accomplished by the much-larger models like GPT-3.
Also:The future of AI is a software story, says Graphcore's CEO
Write Soltan and team, "AlexaTM 20B performs slightly better than similar sized models, however, we did not observe the gain that much larger models like GPT3 175B show from such special prompts," meaning, clues given to the program about the next step in a problem.
"The results indicate that scaling up the model parameters is crucial in performing well in 'reasoning' tasks as was previously demonstrated [...] in decoder-only architectures using Instruct-GPT3 models."
Focusing on the successful task,s such as summarization, the main conclusion that Soltan and team arrive at is that their mixed approach to training the program -- using both objectives of de-noising and causal language modeling -- is a key to making things more efficient.
"This suggests that mixed pre-training, and not necessarily additional multitask training [...] is the key to train strong seq2seq-based Large-scale Language Models (LLM)," they write.
To return to the original question of size, as has been noted in many contexts, the energy usage of increasingly large AI programs is an ethical concern within AI practices. The authors make a strong case for the relevance of their more-efficient approach.
Also:Ethics of AI: Benefits and risks of artificial intelligence
Because the AlexaTM 20B "is much smaller in size than models like GPT3 175B, yet achieving similar or better performance across different tasks," they write, "the ongoing environmental impact of using AlexaTM 20B for inference is much lower than that of larger models (roughly 8.7 times lower)."
They add, "Hence, overtime, AlexaTM 20B has [a] lower carbon footprint as well."
The authors offer a table of stats showing the relative carbon footprint, and there's a big difference in the numbers.
This is an Amazon 2022 AlexTM 20B comparison chart of carbon footprints.
AmazonThat table of carbon footprints is perhaps the most interesting aspect of all this. More deep learning research is going to seek to put up scores for environmental assessments, it would seem, in order to show how energy-efficient a given approach can be. That's in keeping with the world's increasing focus on "ESG," meaning, environmental, social, and governance factors, in all things.
That may mean that being eco-conscious has in some ways become part of the objective of mainstream AI research.
Also:AI in sixty seconds
 Hot Tags :
Artificial Intelligence
Innovation
Hot Tags :
Artificial Intelligence
Innovation
Register Email now for Weekly Promotion Stock
100% free, Unsubscribe any time!
Add 1: Room 605 6/F FA YUEN Commercial Building, 75-77 FA YUEN Street, Mongkok KL, HongKong Add 2: Room 405, Building E, MeiDu Building, Gong Shu District, Hangzhou City, Zhejiang Province, China
Whatsapp/Tel: +8618057156223 Tel: 0086 571 86729517 Tel in HK: 00852 66181601
Email: info@hi-network.com
 English
English Pусский
Pусский Français
Français Español
Español Português
Português

